 Онлайн Радио 24
Онлайн Радио 24 Основы парсинга на Python: от Requests до Selenium

Бывают ситуации, когда нужно автоматизировать сбор и анализ данных из разных источников. Например, если хочется мониторить курс рубля в режиме реального времени. Для решения подобных задач применяют парсинг.
В этой статье кратко рассказываем, как парсить данные веб-сайтов с помощью Python. Пособие подойдет новичкам и продолжающим — сохраняйте статью в закладки и задавайте вопросы в комментариях. Подробности под катом!
Дисклеймер: в статье рассмотрена только основная теория. На практике встречаются нюансы, когда нужно, например, декодировать спаршенные данные, настроить работу программы через xPath или даже задействовать компьютерное зрение. Обо всем этом — в следующих статьях, если тема окажется интересной.
Что такое парсинг?
Парсинг — это процесс сбора, обработки и анализа данных. В качестве их источника может выступать веб-сайт.
Парсить веб-сайты можно несколькими способами — с помощью простых запросов сторонней программы и полноценной эмуляции работы браузера. Рассмотрим первый метод подробнее.

Парсинг с помощью HTTP-запросов
Суть метода в том, чтобы отправить запрос на нужный ресурс и получить в ответ веб-страницу. Ресурсом может быть как простой лендинг, так и полноценная, например, социальная сеть. В общем, все то, что умеет «отдавать» веб-сервер в ответ на HTTP-запросы.
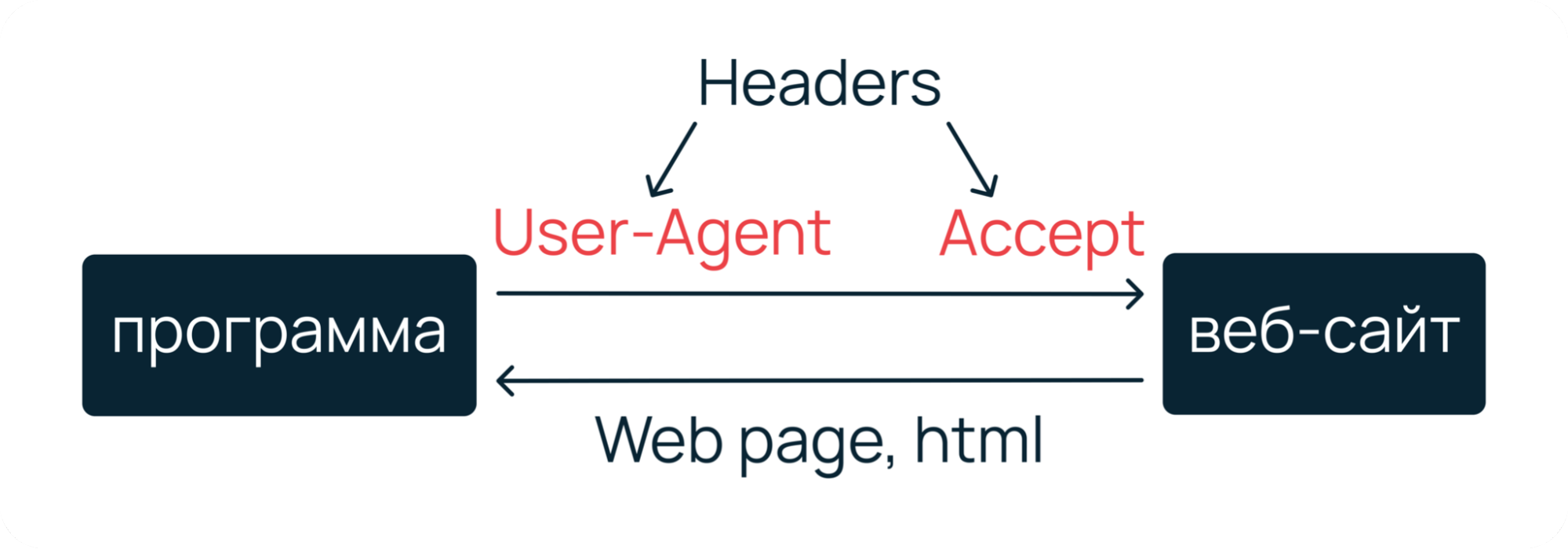
Чтобы сымитировать запрос от реального пользователя, вместе с ним нужно отправить на веб-сервер специальные заголовки — User-Agent, Accept, Accept-Encoding, Accept-Language, Cache-Control и Connection. Их вы можете увидеть, если откроете веб-инспектор своего браузера.

Наиболее подробно о HTTP-запросах, заголовках и их классификации мы рассказали в отдельной статье.
Подготовка заголовков
На самом деле, необязательно отправлять с запросом все заголовки. В большинстве случаев достаточно User-Agent и Accept. Первый заголовок поможет сымитировать, что мы реальный пользователь, который работает из браузера. Второй — укажет, что мы хотим получить от веб-сервера гипертекстовую разметку.
st_accept = "text/html" # говорим веб-серверу, # что хотим получить html # имитируем подключение через браузер Mozilla на macOS st_useragent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 12_3_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Safari/605.1.15" # формируем хеш заголовков headers =
После формирования заголовков нужно отправить запрос и сохранить страницу из ответа веб-сервера. Это можно сделать с помощью нескольких библиотек: Requests, ScraPy или PySpider.
Requests: получаем страницу по запросу
Для начала работы будет достаточно Requests — он удобнее и проще, чем привычный модуль urllib.
Requests — это библиотека на базе встроенного пакета urllib, которая позволяет легко отправлять различные веб-запросы, а также управлять кукисами и сессиями, авторизацией и автоматической организацией пула соединений.
Для примера попробуем спарсить страницу с курсами в Академии Selectel — это можно сделать за несколько действий:
# импортируем модуль import requests … # отправляем запрос с заголовками по нужному адресу req = requests.get("https://selectel.ru/blog/courses/", headers) # считываем текст HTML-документа src = req.text print(src) Пример: парсинг страницы с курсами в Академии Selectel.
Сервер вернет html-страницу, который можно прочитать с помощью атрибута text.
… Курсы - Блог компании Селектел … Супер — гипертекстовую разметку страницы с курсами получили. Но что делать дальше и как извлечь из этого многообразия полезные данные? Для этого нужно применить некий «парсер для выборки данных».
Beautiful Soup: извлекаем данные из HTML
Извлечь полезные данные из полученной html-страницы можно с помощью библиотеки Beautiful Soup.
Beautiful Soup — это, по сути, анализатор и конвертер содержимого html- и xml-документов. С помощью него полученную гипертекстовую разметку можно преобразовать в полноценные объекты, атрибуты которых — теги в html.
# импортируем модуль from bs4 import BeautifulSoup … # инициализируем html-код страницы soup = BeautifulSoup(src, 'lxml') # считываем заголовок страницы title = soup.title.string print(title) # Программа выведет: Курсы - Блог компании Селектел Готово. У нас получилось спарсить и напечатать заголовок страницы. Где это можно применить — решать только вам. Например, мы в Selecte на базе Requests и Beautiful Soup разработали парсер данных с Хабра. Он помогает собирать и анализировать статистику по выбранным хабраблогам. Подробнее о решении можно почитать в предыдущей статье.
Проблема парсинга с помощью HTTP-запросов
Бывают ситуации, когда с помощью простых веб-запросов не получается спарсить все данные со страницы. Например, если часть контента подгружается с помощью API и JavaScript. Тогда сайт можно спарсить только через эмуляцию работы браузера.
Интересен Python? Мы собрали самые интересные и популярные запросы разработчиков в одном файле! По ссылке — материалы по геймдеву, машинному обучению, программированию микроконтроллеров и графических интерфейсов.
Парсинг с помощью эмулятора
Для эмуляции работы браузера необходимо написать программу, которая будет как человек открывать нужные веб-страницы, взаимодействовать с элементами с помощью курсора, искать и записывать ценные данные. Такой алгоритм можно организовать с помощью библиотеки Selenium.
Настройка рабочего окружения
1. Установите ChromeDriver — именно с ним будет взаимодействовать Selenium. Если вы хотите, чтобы актуальная версия ChromeDriver подтягивалась автоматически, воспользуйтесь webdriver-manager. Далее импортируйте Selenium и необходимые зависимости.
pip3 install selenium from selenium import webdriver as wd 2. Инициализируйте ChromeDriver. В качестве executable_path укажите путь до установленного драйвера.
browser = wd.Chrome("/usr/bin/chromedriver/") Теперь попробуем решить задачу: найдем в Академии Selectel статьи о Git.
Задача: работа с динамическим поиском
При переходе на страницу Академии встречает общая лента, в которой собраны материалы для технических специалистов. Они помогают прокачивать навыки и быть в курсе новинок из мира IT.

Но материалов много, а у нас задача — найти все статьи, связанные с Git. Подойдем к парсингу системно и разобьем его на два этапа.
Шаг 1. Планирование
Для начала нужно продумать, с какими элементами должна взаимодействовать наша программа, чтобы найти статьи. Но здесь все просто: в рамках задачи Selenium должен кликнуть на кнопку поиска, ввести поисковый запрос и отобрать полезные статьи.

Теперь скопируем названия классов html-элементов и напишем скрипт!
Шаг 2. Работа с полем ввода
Работа с html-элементами сводится к нескольким пунктам: регистрации объектов и запуску действий, которые будет имитировать Selenium.
. # регистрируем кнопку "Поиск" и имитируем нажатие open_search = browser.find_element_by_class_name("header_search") open_search.click() # регистрируем текстовое поле и имитируем ввод строки "Git" search = browser.find_element_by_class_name("search-modal_input") search.send_keys("Git") Осталось запустить скрипт и проверить, как он отрабатывает:

Скрипт работает корректно — осталось вывести результат.
Шаг 3. Чтение ссылок и результат
Вне зависимости от того, какая у вас задача, если вы работаете с Requests и Selenium, Beautiful Soup станет серебряной пулей в обоих случаях. С помощью этой библиотеки мы извлечем полезные данные из полученной гипертекстовой разметки.
from bs4 import BeautifulSoup . # ставим на паузу, чтобы страница прогрузилась time.sleep(3) # загружаем страницу и извлекаем ссылки через атрибут rel soup = BeautifulSoup(browser.page_source, 'lxml') all_publications = \ soup.find_all('a', )[1:5] # форматируем результат for article in all_publications: print(article['href']) Готово — программа работает и выводит ссылки на статьи о Git. При клике по ссылкам открываются соответветствующие страницы в Академии Selectel.
Что такое парсинг

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Парсинг — это сопоставление строки естественного языка или языка программирования с формальными правилами.
Парсинг — это инструмент работы со строковыми данными. Приведем пример, чтобы было понятно.
Представьте себя радистом на войне. Вы получаете зашифрованное сообщение. У вас есть правила дешифровки. Вы начинаете разгадывать послание согласно этому методу.
Вы смотрите вначале на символ из полученного сообщения. Потом на свою таблицу с его значением. Например, цифре “1” соответствует буква “Я”. Вы сопоставляете все символы и получаете то сообщение, которое можно прочитать.
Парсинг работает точно так же. Есть некоторый шаблон сообщения, написанный на формальном языке. С ним сравнивается какая-то строка.
Парсинг применяется в программировании, в аналитике. Может быть полезен в любой области, где есть возможность работы со строковыми данными.
Парсинг сайта — что это
В общем случае, парсинг строит шаблон последовательности символов. Например, может использоваться древовидная структура. Она показывает, в какой последовательности в строке встречаются символы. Может указывать на приоритет, если речь идет о математическом выражении.
Такие структуры нужны для анализа данных.
Парсить можно и интернет-ресурсы. Это делают, когда нужно понять, какой контент содержится на странице.
Найти на страницах сайта только ту информацию, которая нужна вам для анализа — это задача парсинга.
Скрипт парсинга работает с текстовой информацией. Он вытягивает нужные данные, представляет их в удобном виде.
Например, вы — владелец интернет-магазина. И вы хотите быстро собрать данные о других магазинах — ваших конкурентах. Вас интересует информация с карточек товаров. Вы хотите понять, как их заполняют конкуренты, что они делают лучше вас. Вы определяете, информация с каких сайтов вам нужна. Выбираете программу или скрипт, которыми будете парсить текст. Запускаете. Программа в одном файле может собрать информацию.
Например, название, цену на товар, категорию и описание. Далее вы уже сможете проанализировать это. Например, решить, какую цену установить для своего ассортимента.
А может, вам нужно поработать с отзывами клиентов? Это тоже задачка для парсинга сайта — собираете нужную информацию в одном месте и читаете, что о вашем конкуренте пишут клиенты.
Этапы парсинга данных
- Сбор контента.
Обычно в программу для парсинга загружается код страницы сайта. И с ним уже работает специальный скрипт — разбивает весь код на лексемы, анализирует, какая информация нужна пользователю. - Извлечение информации.
Пользователю не нужна вся информация со страницы. Вернемся к примеру выше. Нас интересуют только отзывы клиентов под конкретными товарами — например, кормом для кошек. Парсер будет находить в коде страницы то место, где указана категория товара: “Корм для кошек”. Далее он определит то место на странице, где размещены комментарии. И извлечет в конечный файл только тексты комментариев. - Сохранение результатов.
Когда вся нужная информация извлечена с сайтов, нужно ее сохранить. Обычно такие данные оформляют в виде таблиц, чтобы было наглядное представление. Можно вносить записи в базу данных. Как будет удобнее аналитику. - Защита сайта от парсинга
Любой владелец сайта хочет защитить свой контент. Кража любой информации — плохо. Ваш контент может появиться на другом ресурсе, ваша статья может перестать считаться уникальной.
Мы расскажем о нескольких методах, как можно предотвратить кражу контента с вашего ресурса. - Разграничение прав доступа.
Это самый простой метод. Вы можете скрыть информацию о структуре сайта. Сделать так, чтобы она была доступна только администраторам. - Установка временной задержки между запросами.
Этот метод хорошо работает, когда на сервер направляются хаотические интенсивные запросы. Они идут от одной машины с разными промежутками. Вы можете установить временную задержку между запросами, поступающими от одной машины. - Создание черного и белого списка.
Это списки пользователей. В белом находятся добропорядочные пользователи. Черный список для тех людей, которые нарушили правила поведения сайта, пытались украсть контент и т. д. - Установка периода обновления страниц.
Чтобы снизить эффективность парсинга, установите время обновления страниц в файле sitemap.xml. Вы можете ограничить частоту запросов, объем загружаемых данных. - Использование методов защиты от роботов.
Сюда относится капча, подтверждение регистрации на ресурсе. То, что сможет выполнить человек, но не сможет проделать машина.
Парсинг может использоваться как во благо, так и во вред. Этот метод помогает проанализировать большие объемы текстовой информации. Но в то же время, проанализировать могут вас, украсть контент, вытащить конфиденциальную информацию, которая не должна попасть в чужие руки.
Парсинг
В Unisender есть все для рассылок: можно создавать и отправлять клиентам письма и SMS, настроить чат-бота и делать рассылки в Telegram и даже собрать простой лендинг для пополнения базы контактов.
Парсинг — это автоматический процесс сбора и систематизации данных в интернете. Для него используют специальные программы — парсеры, которые отбирают с сайтов информацию по заданным критериям.
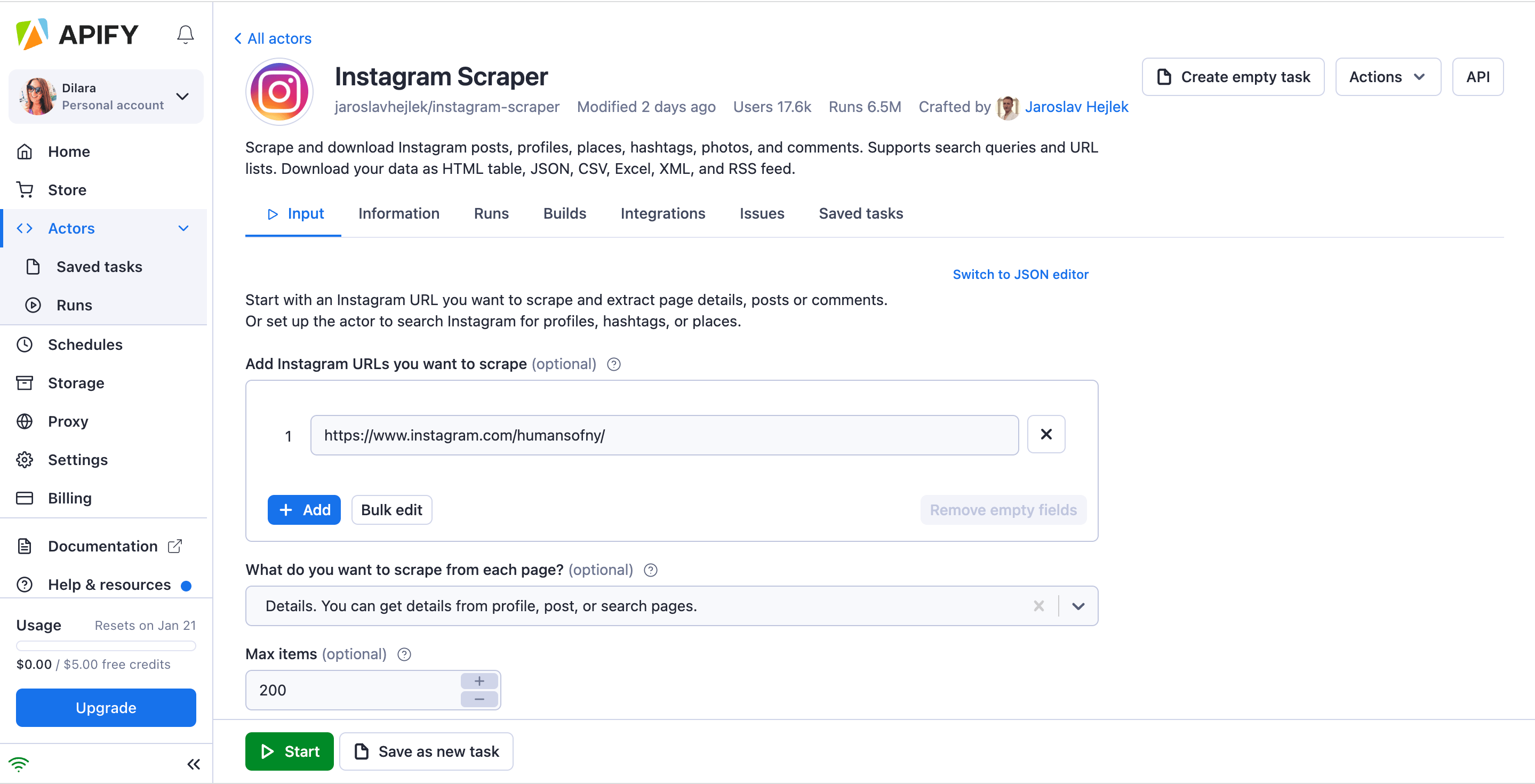
Личный кабинет сервиса для парсинга постов и профилей в Instagram* в программе Apify
Зачем нужен парсинг
Анализ конкурентов . Парсер поможет собрать информацию о том, какие товары и по каким ценам продают другие компании.
SEO-продвижение . При помощи парсинга вы можете собрать семантическое ядро, найти ошибки на своем сайте, проанализировать поисковую выдачу.
Запуск рекламы . Парсинг позволяет собрать базу целевой аудитории или найти потенциальные рекламные площадки.
Наполнение сайтов . Парсинг помогает наполнить сайты, на которые требуется большой объем информации. Например, распространена схема, когда парсят иностранные сайты и переводят информацию о товарах на нужный язык.
Анализ контента . Вы можете проанализировать посты, комментарии, сообщения, хештэги и другой контент, чтобы лучше понять поведение и потребности аудитории.
Сквозная аналитика . Парсер интегрируется с нужной площадкой, автоматически сводит данные о бюджетах и результатах сделок, подсчитывает окупаемость рекламных кампаний.
Как работает парсинг
Процесс парсинга можно схематично разделить на три шага.
- Вы указываете в программе условия, по которым нужно найти данные.
- Парсер сканирует код указанных сайтов — их называют целевыми — и ищет нужные данные.
- Собранные данные выводятся в отчете или собираются в таблицу.
Например, вы выходите на рынок товаров для животных и хотите узнать, какие цены устанавливают конкуренты на аналогичные продукты. Вы указываете в парсере товары, на которые нужно найти цены, выбираете нужный регион, перечисляете сайты конкурентов и запускаете программу.
Парсер анализирует указанные сайты, находит нужные товары и собирает расценки в единую базу. После окончания анализа программа формирует отчет — и вы можете наглядно увидеть ценовую политику в вашей отрасли.
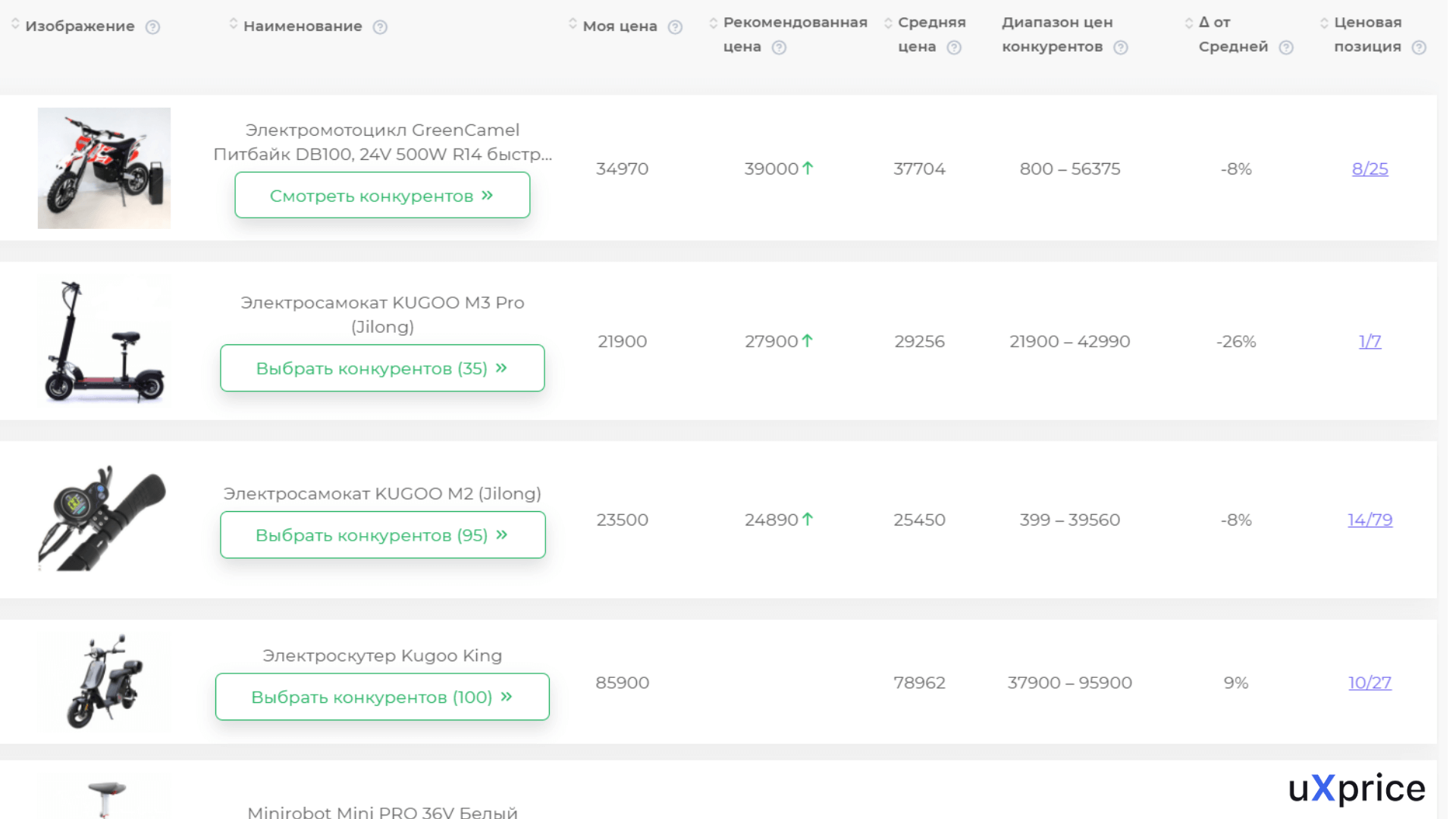
Отчет о ценовой политике конкурентов на рынке электротранспорта в сервисе uXprice. Источник
Законность парсинга
Несмотря на большое количество плюсов, парсинг часто считают «серым» инструментом продвижения из-за последствий, к которым он может привести. Поэтому нужно учитывать некоторые нюансы.
Сам по себе сбор данных из открытых источников законом не запрещен — программы просто автоматизируют то, что маркетолог может сделать вручную. Право искать общедоступную информацию и использовать ее по своему усмотрению гарантируют статья 29 Конституции и статья 7 Закона об информации . При этом и искать, и использовать информацию нужно с соблюдением законодательства — и тут в силу вступают другие правовые нормы:
- Если при помощи парсеров вы полностью копируете информацию с сайтов конкурентов на собственный ресурс, это может привести к нарушению интеллектуального права.
- Чрезмерно агрессивный парсер может создать большую нагрузку на целевой сайт, которая будет выглядеть как DDOS-атака. Если вы парсите такой программой интернет-магазин, то он может стать недоступным на несколько часов, и владельцы сайта потерпят убытки. Даже если сайт не «приляжет», могут возрасти затраты на обслуживание серверов.
- В 272 статье Уголовного кодекса предусмотрена ответственность за «неправомерный доступ к охраняемой законом информации». Эта формулировка включает в себя персональные данные или коммерческую тайну. Например, нельзя парсить чужие списки клиентов, защищенную от несанкционированного доступа информацию, адреса электронной почты для последующей рассылки.
- Согласно поправкам 2021 года к Закону о персональных данных , для сбора и использования даже находящихся в открытом доступе персональных данных нужно получить согласие пользователя. Строго говоря, один из популярных способов использовать парсеры — собирать данные пользователей для запуска таргетированной рекламы — тоже незаконен. Но установить факт парсинга данных при запуске рекламы сейчас технически невозможно, поэтому многие компании продолжают использовать этот инструмент.
Вывод: парсить можно, главное, чтобы этот процесс не приводил к случаям, когда может возникнуть дополнительная ответственность. В частности нельзя продавать полученные данные, использовать персональные данные для рекламы и рассылок, копировать информацию на собственные ресурсы, создавать чрезмерную нагрузку на целевой сайт.
Плюсы парсинга
- Он ускоряет процесс сбора данных. Все эти действия обычно можно совершить вручную, но программа автоматизирует процесс и позволяет получить результат значительно быстрее.
- В программе можно тонко настроить параметры для сбора данных.
Парсер TargetHunter позволяет найти слушателей конкретного музыканта
- Парсинг защищает от ошибок, вызванных человеческим фактором.
- Парсер позволяет сэкономить бюджет как на сборе данных (вместо большого количества сотрудников процесс выполняет одна программа), так и на оптимизации рекламных кампаний. Например, парсеры социальных сетей позволяют более тонко настроить таргетированную рекламу, а значит, сэкономить на продвижении.
Парсинг можно проводить регулярно и автоматически: например, еженедельно отслеживать изменение цен конкурентов.
Виды парсинга
Парсинг товаров . Программа собирает информацию из каталога интернет-магазинов. На основе этих данных можно анализировать ассортимент конкурентов, заполнять страницы собственного сайта.
Парсинг цен . Позволяет проанализировать цены конкурентов и отслеживать изменения в ценовой политике.
Парсинг для SEO . Программа анализирует семантическое ядро целевых сайтов. Данные можно использовать как для наполнения собственного сайта ключевыми словами, так и для контекстной рекламы. Также этот вид парсинга используют, чтобы найти ошибки в мета-тегах, дублирующие элементы, битые ссылки и другие недочеты на собственном сайте.
Парсинг контактов . При этом виде парсинга программа собирает адреса электронной почты, номера телефонов и другую контактную информацию, которая находится в открытом доступе.
Парсинг аудитории . Помогает найти потенциальных клиентов, как правило, среди пользователей социальных сетей. Этот вид парсинга обычно используют для настройки таргетированной рекламы.
Парсинг выдачи . Выявляет лидеров поисковой выдачи по заданным ключевым словам и предоставляет дополнительную информацию — тип сниппета, заголовок, описание, анкоры, связанные ключевые слова. Можно использовать для анализа конкурентов или поиска подходящих рекламных площадок — это позволит размещать рекламу на ресурсах, которые лучше всего индексируются по нужным ключевым словам.
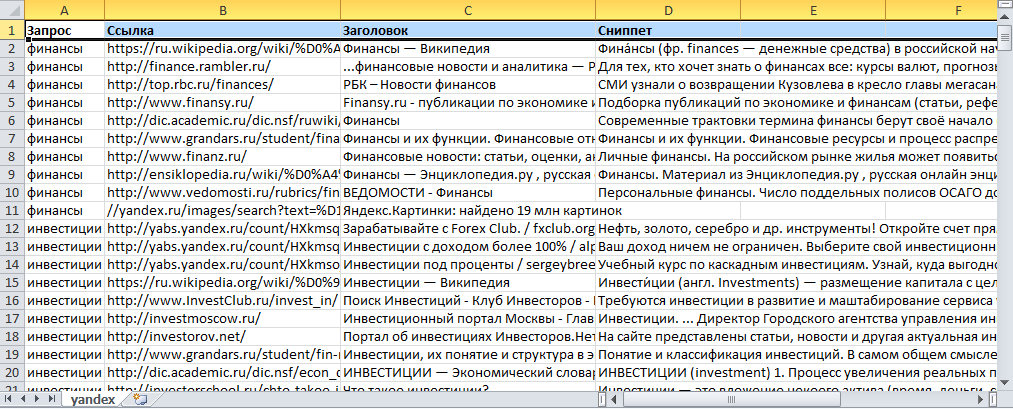
Результатом парсинга выдачи может быть Excel-таблица со всеми интересующими данными: запросом, ссылкой, заголовком, сниппетом. Источник
Возможности парсинга почти безграничны. Например, помимо всем известного парсинга соцсетей или сайтов для анализа конкурентов, мы также парсим ТГ-чаты или сайты для хантинга сотрудников — в них можно отыскать много полезного. Поэтому лучше не фокусироваться на популярных примерах парсинга, а искать свои варианты.
Head of marketing в digital-агентстве i-Media
Программы для парсинга
Программу для парсинга можно разработать самостоятельно, а можно воспользоваться уже готовыми решениями. Вот несколько вариантов:
- Облачные парсеры сайтов: Диггернаут , Import.io , Apify , Mozenda (есть и десктопная версия).
- Десктопные парсеры сайтов: ParserOK , Neatpeak Spider , ComparseR , Parsehub (бесплатный)
- Парсеры социальных сетей: Церебро Таргет , TargetHunter , Pepper.Ninja .
- Парсеры email-адресов: Scrapp.io , Scrapebox Email Scraper .
Как правило, большинство парсеров предоставляют бесплатную версию, но она ограничена либо по времени, либо по возможностям.
При подготовке материала использовались источники:
https://habr.com/ru/companies/selectel/articles/754674/
https://semantica.in/blog/chto-takoe-parsing.html
https://www.unisender.com/ru/glossary/chto-takoe-parsing/