 Онлайн Радио 24
Онлайн Радио 24 Что такое data science и как это работает?
Data science, big data, машинное обучение — вы наверняка слышали эти громкие слова, но насколько понятным был для вас их смысл? Для кого-то они являются красивыми маркетинговыми приманками. Кто-то думает, что data science — это магия, которая бесплатно заставит машину делать, что прикажут. Другие и вовсе полагают, что это легкий способ зарабатывать огромные деньги. Мы в своей авторской колонке на Rusbase расскажем, что это такое простым и понятным языком.
Я работаю в сфере автоматической обработки естественного языка, одного из приложений data science, и часто наблюдаю, как люди не совсем корректно употребляют эти термины, поэтому мне захотелось внести немного ясности. Эта статья для тех, кто плохо представляет себе, что такое data science и хочет разобраться в понятиях.
Определимся с терминологией
Начнем с того, что на самом деле никто точно не знает, что такое data science, и строгого определения не существует — это очень широкий и междисциплинарный концепт. Поэтому здесь я поделюсь своим видением, которое совсем не обязательно совпадает с мнением других.
Термин data science на русский переводят как «наука о данных», а в профессиональной среде часто просто транслитерируют — «дата сайенс». Формально это набор некоторых взаимосвязанных дисциплин и методов из области информатики и математики. Звучит слишком абстрактно, правда? Давайте разбираться.
Первая часть: data
Первая составляющая науки о данных, то, без чего весь дальнейший процесс невозможен, — это, собственно, сами данные: как их собирать, хранить и обрабатывать, а также как выделять из общего массива данных полезную информацию. Именно очистке данных и приведению их к нужному виду специалисты посвящают до 80% своего рабочего времени.
Важная часть этого пункта — как обращаться с данными, для которых не подходят стандартные способы хранения и обработки из-за их огромного объема и/или разнообразия — так называемые большие данные, big data. Кстати, не дайте себя запутать: big data и data science — не синонимы: скорее, первое подраздел второго. При этом не всегда специалистам по анализу данных на практике приходится работать именно с большими данными — полезными могут быть и маленькие.
Соберем данные
Чтобы не быть голословным, я приведу простой пример. Соберем какие-нибудь данные.
Представьте, что нас интересует, есть ли какая-то взаимосвязь между тем, сколько ваши коллеги по работе выпивают кофе за день, и тем, сколько они спали накануне. Запишем доступную нам информацию: допустим, ваш коллега Григорий сегодня спал 4 часа, так что ему пришлось выпить 3 чашки кофе; Эллина спала 9 часов и не пила кофе вообще; а Полина спала все 10 часов, но выпила 2,5 чашки кофе — и так далее.
Изобразим полученные данные на графике (визуализация — тоже немаловажный элемент любого data science-проекта). Отложим по оси X время в часах, а по оси Y — кофе в миллилитрах. Получим что-то вроде такого:
Вторая часть: science
У нас есть данные, что теперь с ними можно делать? Правильно, анализировать, извлекать полезные закономерности и как-то их использовать. Тут нам помогут такие дисциплины, как статистика, машинное обучение, оптимизация.
Они формируют следующую и, возможно, самую важную составляющую data science — анализ данных. Машинное обучение позволяет находить закономерности в существующих данных, чтобы затем предсказывать нужную информацию для новых объектов.
Проанализируем данные
Вернемся к нашему примеру. На глаз кажется, что два параметра как-то взаимосвязаны: чем меньше человек спал, тем больше он выпьет кофе на следующий день. При этом у нас есть и выбивающийся из этой тенденции пример — любительница поспать и попить кофе Полина. Тем не менее можно попытаться приблизить полученную закономерность некоторой общей прямой линией так, чтобы она максимально близко подходила ко всем точкам:
Зеленая линия — и есть наша модель машинного обучения, она обобщает данные и ее можно описать математически. Теперь с помощью нее мы можем определять значения для новых объектов: когда мы захотим предсказать, сколько кофе сегодня выпьет вошедший в кабинет Никита, мы поинтересуемся, сколько он спал. Получив в качестве ответа значение в 7,5 часов, подставим его в модель — ему соответствует количество выпитого кофе в объеме чуть менее 300 мл. Красная точка обозначает наше предсказание.
Примерно так и работает машинное обучение, идея которого очень проста: найти закономерность и распространить ее на новые данные. На самом деле, в машинном обучении выделяется еще один класс задач, когда нужно не предсказывать какие-то значения, как в нашем примере, а разбивать данные на некоторые группы. Но об этом мы подробнее поговорим в другой раз.
Применим результат
Однако на мой взгляд, data science не заканчивается на выявлении закономерностей в данных. Любой data science-проект — это прикладное исследование, где важно не забывать о таких вещах, как постановка гипотезы, планирование эксперимента и, конечно, оценка результата и его пригодности для решения конкретного кейса.
Последнее очень важно в реальных бизнес-задачах, когда необходимо понять, принесет ли найденное data science решение пользу вашему проекту или нет. Какова могла бы быть полезность построенной модели в нашем примере? Возможно, с ее помощью мы могли бы оптимизировать доставку кофе в офис. При этом нам нужно оценить риски и определить, лучше наша ли наша модель справлялась бы с этим, чем существующее решение — офис-менеджер Михаил, ответственный за закупку продукта.
Найдем исключения
Конечно, наш пример максимально упрощен. В реальности можно было бы построить более сложную модель, которая учитывала бы какие-то другие факторы, например, любит ли человек кофе в принципе. Или модель могла бы находить более сложные, чем представляемые прямой линией, взаимосвязи.
Можно было бы сперва найти в наших данных выбросы — объекты, которые, как Полина, сильно непохожи на большинство других. Дело в том, что при реальной работе такие примеры могут плохо повлиять на процесс построения модели и ее качество, и их имеет смысл обрабатывать как-то иначе. А иногда такие объекты представляют первостепенный интерес, например, в задаче обнаружения аномальных банковских транзакций с целью предотвращения мошенничества.
Кроме того, Полина демонстрирует нам еще одну важную идею — несовершенство алгоритмов машинного обучения. Наша модель прогнозирует всего 100 мл кофе для человека, который спал 10 часов, в то время как на самом деле Полина выпила аж целых 500. В это никогда не поверят заказчики data science-решений, но пока еще невозможно научить машину идеально предсказывать все на свете: как бы хорошо мы ни выделяли закономерности в данных, всегда найдутся непредсказуемые элементы.
Продолжим рассказ
Итак, data science — это набор методов обработки и анализа данных и применение их к практическим задачам. При этом надо понимать, что у каждого специалиста свой взгляд на эту сферу и мнения могут отличаться.
В основе data science лежат достаточно простые идеи, однако на практике часто обнаруживается много неочевидных тонкостей. Как data science окружает нас в повседневной жизни, какие существуют методы анализа данных, из кого состоит команда data science и какие сложности могут возникнуть в процессе исследования — об этом мы расскажем в следующих статьях.
Data Science для начинающих: обзор сферы и профессий
Давайте разберёмся, что представляет из себя Data Science и как построить карьеру в сфере работы с данными.
Что такое Data Science
Data Science — наука о данных и их анализе. Сфера охватывает сбор больших массивов структурированных и неструктурированных данных и преобразование их в человекочитаемый формат. Преобразование включает в себя визуализацию, работу со статистикой и аналитическими методами — машинным и глубоким обучением, анализом вероятностей и построением предиктивных моделей, построением нейронных сетей и их применением для решения актуальных задач.
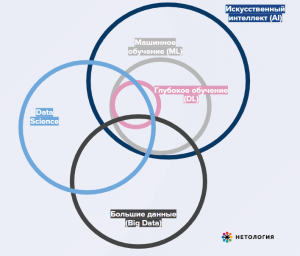
Начнём с определения терминов.
Искусственный интеллект — обучение машин «думать» для упрощения рутинных процессов и освобождения людского ресурса для творческих задач. Используется в персонализации, цифровых двойниках, имитации человеческого мышления, алгоритмах-игроках.
Первыми моделями ИИ считают машины Тьюринга, созданные в 1936 году. Несмотря на долгую историю, ИИ в большинстве областей ещё не способен полностью заменить человека. И соревнования искусственного интеллекта с человеком в шахматах, и шифрование данных — две стороны одной медали.

Елена Герасимова
Руководитель факультета «Аналитика и Data Science» в Нетологии
Машинное обучение (Machine learning, ML) — создание инструментов для извлечения знаний из данных. Это рекомендательные системы, предсказательные (предиктивные) алгоритмы, распознавание образов, перевод картинок в текст, синтез текстов. В ML модели могут обучаться на данных самостоятельно или поэтапно: обучение с учителем, то есть наличие подготовленных человеком данных ⟶ обучение без учителя, работа со стихийными, зашумлёнными данными.
Глубокое обучение — создание многослойных нейронных сетей в областях, где нужен более продвинутый или быстрый анализ и традиционное машинное обучение не справляется. «Глубину» обеспечивает более чем один скрытый слой нейронов в сети, которая проводит математические вычисления.
Используется в дип-фейках, «масках» в приложениях, высокоточных автопилотах, синтезе изображений, голоса и звука.
Data Science — понимание и придание смысла данным, визуализация, сбор инсайтов и принятие на основе данных решений. Специалисты направления используют некоторые методы машинного обучения и Big Data — облачные вычисления, инструменты создания виртуальной среды разработки и многое другое.
Применяется для автоматизации, ускорения исследований, моделирования. Обеспечивает сочетание разных подходов и математически доказанную значимость в принятии решений.
Big Data (Большие данные) — совокупность подходов к огромным объёмам неструктурированных данных. Это данные соцсетей, медиатеки, стриминг данных, банковские транзакции, события в MMORG.
Специфика сферы — инструменты и системы, способные выдержать высокую нагрузку.
Как и где зарабатывать на данных
- Собирать и продавать данные — в соцсетях, поисковых системах, медиа.
- Обслуживать данные — в софтверных компаниях-гигантах Google, Amazon и других.
- Разрабатывать продукты c data-решениями — в компаниях, которые создают беспилотники и другую инновационную технику.
- Извлекать из данных пользу — в рекомендательных системах, сервисах прогноза погоды и других сферах, полезных рядовым пользователям.
Самая обширная сфера — извлечение пользы из данных. Она охватывает:
- обнаружение аномалий — аномального поведения клиентов, мошенничества;
- персонализированный маркетинг — персональные email-рассылки, ретаргетинг, рекомендательные системы;
- прогнозы метрик — показателей эффективности, качества рекламных кампаний и других направлений деятельности;
- скоринговые системы — обрабатывают большие объёмы данных и помогают принять решение, например, о выдаче кредита;
- базовое взаимодействие с клиентом — стандартные ответы в чатах, голосовые помощники, сортировка писем по папкам.
Из чего состоит аналитика данных
Сбор. Поиск каналов, где можно собирать данные, и способов их получения.
Проверка. Валидация, отсечение аномалий, которые не влияют на результат и сбивают с толку при дальнейшем анализе.
Анализ. Изучение данных, подтверждение предположений, выводы.
Визуализация. Представление в таком виде, который будет простым и понятным для восприятия человеком — в графиках, диаграммах.
Действие. Принятие решений на основе проанализированных данных, например, о смене маркетинговой стратегии, увеличении бюджета на какое-либо направление деятельности компании.
Кем можно работать в аналитических проектах
Аналитики McKinsey еще в 2012 году предсказали дефицит специалистов по данным. Только в США в 2018 году нехватка составила 140‒190 тысяч человек. Недостаток менеджеров, которые могут задавать аналитикам правильные вопросы, ещё больше — 1,5 миллионов человек. Прогнозы подтвердились: специалистов действительно не хватает.
Что такое Data Science

Поговорим о том, что такое Data Science, почему она так важна для бизнеса и стоит ли самому становиться специалистом в этой области. Кратко об одной из самых востребованных профессий в мире.
Определение Data Science
Data Science (наука о данных, даталогия) – это набор дисциплин, технологий и методик для анализа огромного объема информации, генерируемой бизнесом и нон-профит-организациями. Такое явление, как Data Science, включает в себя подготовку ко сбору данных, их обработку и презентацию добытой информации нужным людям в нужном ключе. Например, руководству для принятия решений по развитию какого-либо продукта или инвесторам для демонстрации показателей вашей компании.
Применение методик Data Science подразумевает использование программных алгоритмов, продвинутых аналитических инструментов, искусственного интеллекта и других современных технологий. Это комплексная процедура, требующая специальных навыков. В связи с чем появилась целое направление в области аналитики и отдельная профессия – дата-сайентист.
От качества сбора данных, точности проведенного анализа, объективной полезности полученных значений и их корректной визуализации во многом зависит судьба как отдельных проектов, так и целых компаний. Поэтому дата-сайентисты так важны и пользуются большим спросом на IT-рынке.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Что делают специалисты в области Data Science?
На плечи Data Science-специалиста ложится весь спектр задач, касающихся сбора и обработки информации, от выбора источников данных до их корректной репрезентации.
Специалист в этой области должен:
- Применять математические структуры, знания в области статистики и уникальные для обработки данных алгоритмы, чтобы управлять гигантскими объемами информации, поступающей из разных источников.
- Использовать широкий ассортимент инструментов и техник: от сортировки строк в SQL-базах данных до интеграции данных в сторонние программные продукты.
- Использовать искусственные интеллект и machine-learing модели, чтобы доставать из полученной информации крупицы наиболее критически важных данных.
- Самому создавать приложения и утилиты для обработки информации.
- Визуализировать и подавать полученные данные так, чтобы другие члены команды, руководство и инвесторы получили ответы на все задаваемые вопросы в рамках своих компетенций.
- Объяснять вышестоящим коллегам, как можно задействовать полученную информацию для улучшения существующих продуктов, повышения прибыли компании или эффективности разработок.
Такой набор навыков в одном сотруднике встречается довольно редко, отсюда и высокие зарплаты у дата-сайентистов вкупе с высоким спросом на специалистов из этой области.
Как устроена наука Data Science
Стандартный рабочий день для Data Science-специалиста обычно включает в себя один из этапов сбора или обработки данных. Весь рабочий процесс состоит из 5 стадий:
- Сбор информации. Включает в себя процессы по сбору структурированных и неструктурированных данных из всех релевантных источников. Используются все подручные инструменты – от ручного ввода и скрапинга веб-страниц до сбора показателей из проприетарных систем.
- Хранение информации. Поиск методов и средств для сохранения полученных данных в таком виде, в котором их впоследствии можно будет обработать, используя заранее предусмотренные для этого механизмы. Дата-сайентист так же должен удалить дубликаты, отфильтровать лишнее и т.п.
- Предобработка. На этом этапе специалист должен проанализировать связи между разными кусками добытых данных, проследить паттерны и соответствие полученной информации.
- Обработка. В этот момент специалист подключает все свои «волшебные» инструменты: искусственный интеллект, модели машинного обучения, аналитические алгоритмы и т.п.
- Коммуникация. По итогу специалист должен оформить найденные данные в виде таблиц, графиков, списков или в любой другой форме, предпочтительной для демонстрации разным категориям потребителей этой самой информации.
Инструменты Data Science
Специалисты в области Data Science хоть и не являются разработчиками, но должны уметь программировать и создавать приложения. В противном случае у них попросту не будет достаточного количества инструментов для обработки данных. Поэтому придется изучить хотя бы один из двух наиболее востребованных в Data Science языков программирования.
- R. Это язык с открытым исходным кодом и программное окружение для создания статистических вычислений. R предлагает большое количество библиотек и инструментов для фильтрации и предобработки данных. Также с помощью него можно визуализировать данные и тренировать модели машинного обучения для корректного взаимодействия с полученной информацией.
- Python. Объектно-ориентированный язык программирования общего назначения. Python настолько универсален, что применяется практически в любых сферах деятельности, включая работу с искусственным интеллектом и обработку числовых значений.
Также дата-сайентисты задействуют в своей деятельности такие инструменты, как Apache Spark, Tableau, Microsoft PowerBI и десятки других, помогающих взаимодействовать с данными.
Как Data Science связана с облачными решениями
Помимо перечисленных выше инструментов, специалистам в области Data Science необходимо ознакомиться с тем, как функционируют облачные решения.
Дело в том, что дата-сайентистам приходится работать с колоссальными объемами данных. Взаимодействовать с ними, используя локальные машины, слишком затратно по времени. Стандартным компьютерам попросту не хватает мощности для запуска массивных процессов по анализу данных и их обработке.
Облачные кластеры позволяют запускать процедуры по обработке и сбору информации в сети, используя масштабные сети компьютеров, связанных между собой.
Для этого используются сервисы в духе Amazon S3, Microsoft Azure и Google Clouds. Они позволяют корпорациям обрабатывать неограниченный поток данных из различных источников, запуская в облачных кластерах специализированное ПО и ИИ-модели на мощных облачных компьютерах.

Также облачные решения упрощают работу Data Science-специалистов, так как им не приходится заниматься поддержкой ПО, его обновлением и т.п.
Примеры использования Data Science
Где же задействуется Data Science и какие паттерны применения уже существуют? Вот, что об этом говорит компания IBM:
- Международные банки используют приложения, которые позволяют при помощи облачных вычислений автоматически выяснить риски кредитования для отдельных клиентов.
- Data Science задействуется технологическими компаниями по разработке автономных средств передвижения. Дата-сайенс-инструменты позволяют обрабатывать информацию на ходу, помогая ИИ-автомобилям передвигаться самостоятельно.
- В бизнесе часто задействуются инструменты, разработанные в тесной интеграции с Data Science-продуктами. В частности, это играет важную роль при роботизации бизнес-процессов.
- Медиакорпорации используют Data Science, чтобы анализировать интересы потребителей.
- В полиции создаются системы на базе ИИ, которые анализируют преступления и генерируют удобоваримые статистические отчеты. Также создаются системы, позволяющие предугадать, как правильно распределить ресурсы полиции, чтобы сократить количество преступлений.
- В здравоохранении разрабатываются инструменты на базе аналитических показателей, позволяющие наблюдать за больными дистанционно.
Стоит ли становиться специалистом в области Data Science?
Это одна из наиболее востребованных профессий на текущий момент. Рынок продолжают расти, повышается количество данных, которые нужно обрабатывать, поэтому спада интереса к аналитикам не произойдет.
Зарплаты дата-сайентистов в России варьируются от 100 000 рублей до 500 000 рублей в зависимости от специфики работы и опыта соискателя.
Сотни открытых вакансий, внушительные бюджеты. Выглядит, как отличная карьера для всех, кто заинтересован в новом для себя направлении. К тому же обучиться Data Science сейчас можно на профильных курсах таких онлайн-школ, как GeekBrains, Skillbox и Coursera.
При подготовке материала использовались источники:
https://medium.com/@irela/%D1%87%D1%82%D0%BE-%D1%82%D0%B0%D0%BA%D0%BE%D0%B5-data-science-%D0%B8-%D0%BA%D0%B0%D0%BA-%D1%8D%D1%82%D0%BE-%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%B0%D0%B5%D1%82-2c9c6455ae4d
https://netology.ru/blog/03-2019-data-science-obzor
https://timeweb.com/ru/community/articles/data-science