 Онлайн Радио 24
Онлайн Радио 24 Stanza
Stanza – простая в использовании программа для чтения текста на вашем компьютере, а также iPhone, iPod Touch и Kindle. Благодаря минималистичному, хорошо организованному интерфейсу, Stanza отлично подходит для чтения цифровых публикаций, в том числе электронных книг, газет, PDF-файлов, веб-контента. Данная программа отличается от других подобных ей вниманием к деталям: настройка переносов, автоматическая прокрутка текста, настройка страницы, удобная навигация по темам. Объемные файлы, которые утомительно читать с помощью веб-браузера или PDF-ридера, легко и естественно воспринимаются со Stanza.
Автор обзора : Алексей Астафьев, 09.01.2014
Ключевые особенности и функции
- встроенная поддржка форматов HTML, PDF, Microsoft Word и Rich Text Format, а также всех основных книжных стандартов: открытого Amazon Kindle и Mobipocket, Microsoft LIT, Palm DOC и нового IDPF (International Digital Publishing Forum);
- открытые API, позволяющие разработчикам реализовывать поддержку собственных форматов документов;
- stanza – больше, чем просто читательская программа, это настоящая читательская платформа;
- программа поддерживает различные текстовые “макеты”, которые удовлетворят вкусы разных читателей, например, стандартный газетный формат, в котором текст располагается несколькими столбцами;
- в Stanza встроен также текстовый макет, представляющий собой единую колонку, которая автоматически прокручивается вертикально на заданной пользователем скорости, что позволяет прочитать содержимое файла без необходимости “перелистывания” страниц вручную;
- вертикальная прокрутка полезна не тоько для чтения текста, но и для просмотра презентаций, созданных в стиле “телесуфлера”, кроме того, данная функция идеально подходит для читателей-инвалидов, которые не в состоянии пользоваться клавиатурой или мышью;
- полноэкранный режим, вертикальная прокрутка, простейший интерфейс, динамическое увеличесние шрифта – все это подойдет детям, пожилым людям или людям с нарушением координации и зрения.
Специальные требования
- 30-дневная триальная версия.
Stanza – A Python NLP Package for Many Human Languages
Stanza is a collection of accurate and efficient tools for the linguistic analysis of many human languages. Starting from raw text to syntactic analysis and entity recognition, Stanza brings state-of-the-art NLP models to languages of your choosing.
Table of contents
About
Stanza is a Python natural language analysis package. It contains tools, which can be used in a pipeline, to convert a string containing human language text into lists of sentences and words, to generate base forms of those words, their parts of speech and morphological features, to give a syntactic structure dependency parse, and to recognize named entities. The toolkit is designed to be parallel among more than 70 languages, using the Universal Dependencies formalism.
Stanza is built with highly accurate neural network components that also enable efficient training and evaluation with your own annotated data. The modules are built on top of the PyTorch library. You will get much faster performance if you run the software on a GPU-enabled machine.
In addition, Stanza includes a Python interface to the CoreNLP Java package and inherits additional functionality from there, such as constituency parsing, coreference resolution, and linguistic pattern matching.
To summarize, Stanza features:
- Native Python implementation requiring minimal efforts to set up;
- Full neural network pipeline for robust text analytics, including tokenization, multi-word token (MWT) expansion, lemmatization, part-of-speech (POS) and morphological features tagging, dependency parsing, and named entity recognition;
- Pretrained neural models supporting 70 (human) languages;
- A stable, officially maintained Python interface to CoreNLP.
Below is an overview of Stanza’s neural network NLP pipeline:
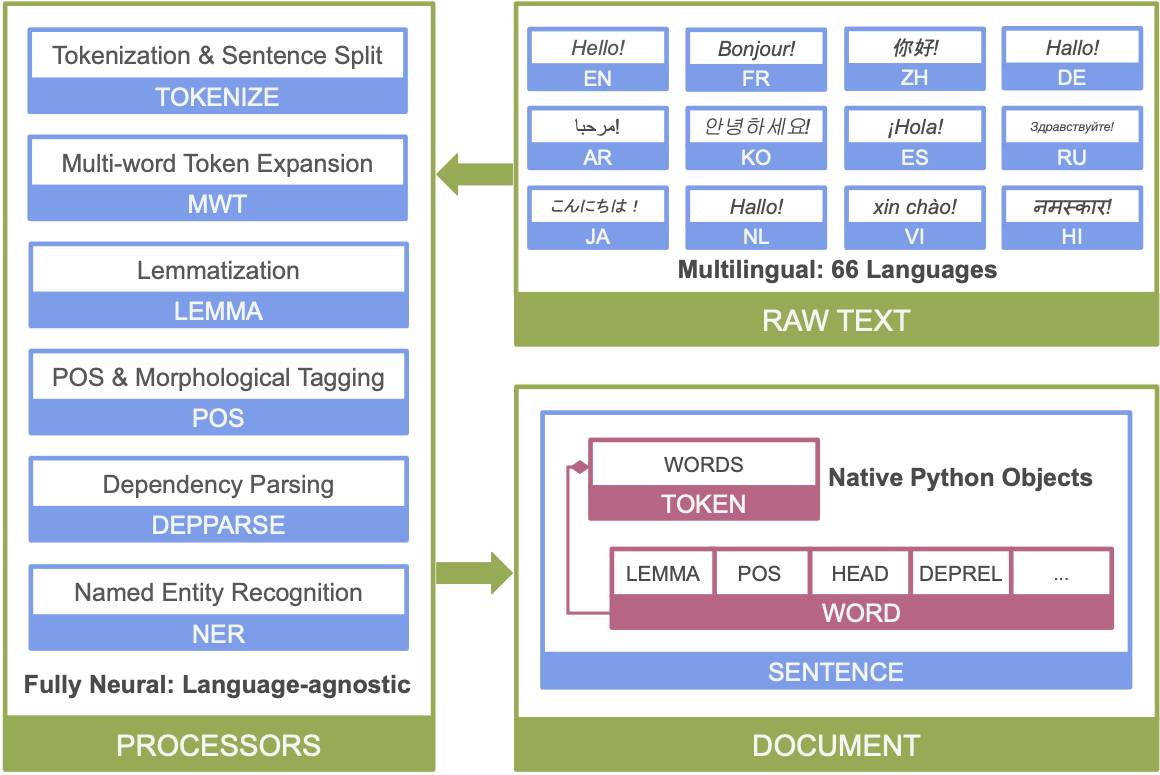
Getting Started
We strongly recommend installing Stanza with pip , which is as simple as:
pip install stanza To see Stanza’s neural pipeline in action, you can launch the Python interactive interpreter, and try the following commands:
>>> import stanza >>> stanza.download('en') # download English model >>> nlp = stanza.Pipeline('en') # initialize English neural pipeline >>> doc = nlp("Barack Obama was born in Hawaii.") # run annotation over a sentence You should be able to see all the annotations in the example by running the following commands:
>>> print(doc) >>> print(doc.entities) For more details on how to use the neural network pipeline, please see our Installation, Getting Started Guide, and Tutorials pages.
Aside from the neural pipeline, Stanza also provides the official Python wrapper for accessing the Java Stanford CoreNLP package. For more details, please see Stanford CoreNLP Client.
If you run into issues or bugs during installation or when you run Stanza, please check out the FAQ page. If you cannot find your issue there, please report it to us via GitHub Issues. A GitHub issue is also appropriate for asking general questions about using Stanza – please search the closed issues first!
License
Stanza is licensed under the Apache License, Version 2.0 (the “License”); you may not use the software package except in compliance with the License. You may obtain a copy of the License at
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
Main Contributors
The PyTorch implementation of Stanza’s neural pipeline is due to Peng Qi, Yuhao Zhang, and Yuhui Zhang, with help from Jason Bolton, Tim Dozat and John Bauer. John Bauer currently leads the maintenance of this package.
The CoreNLP client is mostly written by Arun Chaganty, and Jason Bolton spearheaded merging the two projects together.
We are also grateful to community contributors for their help in improving Stanza.
Citing Stanza in papers
If you use Stanza in your work, please cite this paper:
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton and Christopher D. Manning. 2020. Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. In Association for Computational Linguistics (ACL) System Demonstrations. 2020. [pdf][bib]
If you use the biomedical and clinical model packages in Stanza, please also cite our JAMIA biomedical models paper:
Yuhao Zhang, Yuhui Zhang, Peng Qi, Christopher D. Manning, Curtis P. Langlotz. Biomedical and Clinical English Model Packages in the Stanza Python NLP Library, Journal of the American Medical Informatics Association. 2021.
If you use Stanford CoreNLP through the Stanza python client, please also follow the instructions here to cite the proper publications.
Links
Copyright © 2020 Stanford NLP Group.
Анализ текста средствами библиотеки Stanza
Для решения задач обработки текстов на естественном языке на сегодняшний день существует множество библиотек для python. В данной статье обратимся к библиотеке Stanza от StanfordNLPGroup, основанной на PyTorch. Т.к. анализ текста является важной NLP-задачей, рассмотрим основные методы, реализованные в данной библиотеке.
3K открытий
Для установки библиотеки используем команду pip install stanza.
Для работы с русскоязычным текстом скачиваем соответствующую модель:
import stanza stanza.download(‘ru’)
Теперь рассмотрим различные этапы анализа (предобработки) текстовых данных.
1. Токенизация.
Разобьём текст на предложения (sentences) и предложения на токены (tokens)
import stanza ppln = stanza.Pipeline(‘ru’, processors=’tokenize’) #инициируем нейронный конвеер (Pipeline) txt = ‘Об орясину осёл топорище точит. А факир выгнав гостей выть акулой хочет.’ doc = ppln(txt) for i, sentence in enumerate(doc.sentences): print(f’====== Предложение =======’) print(*[f’id: \ttext: ‘ for token in sentence.tokens], sep=’\n’)
Получаем следующий список предложений и токенов:
====== Предложение 1 ======= id: (1,) text: Об id: (2,) text: орясину id: (3,) text: осёл id: (4,) text: топорище id: (5,) text: точит id: (6,) text: . ====== Предложение 2 ======= id: (1,) text: А id: (2,) text: факир id: (3,) text: выгнав id: (4,) text: гостей id: (5,) text: выть id: (6,) text: акулой id: (7,) text: хочет id: (8,) text: .
2. POS-tagging
Теперь проведём пример с частеречной разметкой (part of speech tagging). При инициализации Pipeline в параметр processors добавляем значение ‘pos’. В качестве результата выводим соответствующие частям речи значения (тэги) в формате universalPOS (upos), а так же дополнительные лексические и грамматические свойства в формате universalmorphologicalfeatures (UFeats)
import stanza ppln = stanza.Pipeline(‘ru’, processors=’tokenize,pos’) txt = ‘Об орясину осёл топорище точит. А факир выгнав гостей выть акулой хочет.’ doc = ppln(txt) print(*[f’word:
Результат будет следующим:
word: Об upos: ADP feats: _ word: орясину upos: NOUN feats: Animacy=Inan|Case=Loc|Gender=Masc|Number=Sing word: осёл upos: NOUN feats: Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing word: топорище upos: NOUN feats: Animacy=Inan|Case=Nom|Gender=Masc|Number=Sing word: точит upos: VERB feats: Aspect=Imp|Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin|Voice=Act word: . upos: PUNCT feats: _ word: А upos: CCONJ feats: _ word: факир upos: NOUN feats: Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing word: выгнав upos: VERB feats: Aspect=Perf|Tense=Past|VerbForm=Conv|Voice=Act word: гостей upos: NOUN feats: Animacy=Anim|Case=Acc|Gender=Masc|Number=Plur word: выть upos: VERB feats: Aspect=Imp|VerbForm=Inf|Voice=Act word: акулой upos: NOUN feats: Animacy=Anim|Case=Ins|Gender=Fem|Number=Sing word: хочет upos: VERB feats: Aspect=Imp|Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin|Voice=Act word: . upos: PUNCT feats:
3. Лемматизация.
Для получения нормальных словарных форм слов, необходимо при инициализации Pipeline в параметр processors добавить значение ‘lemma’. И в результат выводим свойство lemma каждого слова (word).
import stanza ppln = stanza.Pipeline(‘ru’, processors=’tokenize,pos,lemma’) txt = ‘Об орясину осёл топорище точит. А факир выгнав гостей выть акулой хочет.’ doc = ppln(txt) print(*[f’word:
Результатом выполнения кода будет:
word: Об upos: о word: орясину upos: орясина word: осёл upos: осел word: топорище upos: топорищ word: точит upos: точить word: . upos: . word: А upos: а word: факир upos: факир word: выгнав upos: выгнать word: гостей upos: гость word: выть upos: выть word: акулой upos: акула word: хочет upos: хотеть word: . upos: .
4. Анализ зависимостей.
По аналогии с предыдущими пунктами добавляем в параметр processors значение ‘depparse’ при инициализации Pipeline. Обработчик depparse строит дерево зависимостей между словами предложений.
import stanza ppln = stanza.Pipeline(‘ru’, processors=’tokenize,pos,lemma,depparse’) txt = ‘Об орясину осёл топорище точит. А факир выгнав гостей выть акулой хочет.’ doc = ppln(txt) print(*[f’word:
В результате видим список с зависимостями — каждому слову сопоставляется вершина и тип синтаксического отношения (deprel) в формате Universal Dependencies:
word: Об head id: 2 head: орясину deprel: case word: орясину head id: 5 head: точит deprel: obl word: осёл head id: 5 head: точит deprel: nsubj word: топорище head id: 3 head: осёл deprel: appos word: точит head id: 0 head: root deprel: root word: . head id: 5 head: точит deprel: punct word: А head id: 7 head: хочет deprel: cc word: факир head id: 7 head: хочет deprel: nsubj word: выгнав head id: 7 head: хочет deprel: advcl word: гостей head id: 3 head: выгнав deprel: obj word: выть head id: 3 head: выгнав deprel: xcomp word: акулой head id: 5 head: выть deprel: obl word: хочет head id: 0 head: root deprel: root word: . head id: 7 head: хочет deprel: punct
В данной статье мы рассмотрели инструментарий библиотеки Stanza по анализу (предобработке) текстовых данных.
С учетом мультиязычности данный проект может составить серьёзную конкуренцию другим NLP-библиотекам на python.
При подготовке материала использовались источники:
https://soft.mydiv.net/win/download-Stanza.html
https://stanfordnlp.github.io/stanza/
https://vc.ru/newtechaudit/358184-analiz-teksta-sredstvami-biblioteki-stanza