 Онлайн Радио 24
Онлайн Радио 24 Saved searches
Use saved searches to filter your results more quickly
Cancel Create saved search
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
goharbor / harbor Public
Architecture Overview of Harbor
Orlix edited this page Jan 30, 2023 · 11 revisions
- Architecture
- Data Access Layer
- Fundamental Services
- Consumers
- The process of docker login
- The process of docker push
Clone this wiki locally
From now on (Version 2.0), Harbor has been evolved to a complete OCI compliant cloud-native artifact registry.
OCI compliant cloud-native artifact registry means it now supports OCI images and OCI image indexes (https://github.com/opencontainers/image-spec/blob/master/image-index.md). An OCI image index is a higher level manifest which points to a list of image manifests, ideal for one or more platforms. For example, Docker manifest list is a popular implementation of the OCI image index. This also means Harbor now fully supports multi-architecture images.
With Harbor V2.0, users can manage images, manifest lists, Helm charts, CNABs, OPAs among others which all adhere to the OCI image specification. It also allows for pulling, pushing, deleting, tagging, replicating, and scanning such kinds of artifacts. Signing images and manifest list are also possible now.
The diagram shown below is the overall architecture of the Harbor registry.

version: 2.0
As depicted in the above diagram, Harbor comprises the following components placed in the 3 layers:
Data Access Layer
k-v storage: formed by Redis, provides data cache functions and supports temporarily persisting job metadata for the job service.
data storage: multiple storages supported for data persistence as backend storage of registry and chart museum. For checking more details, please refer to the driver list document at docker website and ChartMuseum GitHub repository.
Database: stores the related metadata of Harbor models, like projects, users, roles, replication policies, tag retention policies, scanners, charts, and images. PostgreSQL is adopted.
Proxy: reverse-proxy formed by the Nginx Server to provide API routing capabilities. Components of Harbor, such as core, registry, web portal, and token services, etc., are all behind this reversed proxy. The proxy forwards requests from browsers and Docker clients to various backend services.
Core: Harbor’s core service, which mainly provides the following functions:
- API Server: A HTTP server accepting REST API requests and responding those requests rely on its submodules such as ‘Authentication & Authorization’, ‘Middleware’, and ‘API Handlers’.
- Authentication & Authorization
- requests are protected by the authentication service which can be powered by a local database, AD/LDAP or OIDC.
- RBAC mechanism is enabled for performing authorizations to the related actions, e.g: pull/push an image
- Token service is designed for issuing a token for every docker push/pull command according to a user’s role of a project. If there is no token in a request sent from a Docker client, the Registry will redirect the request to the token service.
- Distribution (docker registry)
- Docker Hub
- Huawei SWR
- Amazon ECR
- Google GCR
- Azure ACR
- Ali ACR
- Helm Hub
- Quay
- Artifactory
- GitLab Registry
- The Trivy scanner provided by Aqua Security, the Anchore Engine scanner provided by Anchore, the Clair scanner sponsored by CentOS (Redhat), and DoSec Scanner provided by DoSec will be supported.
- At present, only container images or bundles are built on top of images like the manifest list/OCI index or CNAB bundle are supported to scan.
- HTTP Post request
- Slack channel
Job Service: General job execution queue service to let other components/services submit requests of running asynchronous tasks concurrently with simple restful APIs
Log collector: Log collector, responsible for collecting logs of other modules into a single place.
GC Controller: manages the online GC schedule settings and start and track the GC progress.
Chart Museum: a 3rd party chart repository server providing chart management and access APIs. To learn more details, check here.
Docker Registry: a 3rd party registry server, responsible for storing Docker images and processing Docker push/pull commands. As Harbor needs to enforce access control to images, the Registry will direct clients to a token service to obtain a valid token for each pull or push request.
Notary: a 3rd party content trust server, responsible for securely publishing and verifying content. To learn more details, check here.
As a standard cloud-native artifact registry, the related clients will be naturally supported, like docker CLI, notary client, OCI compatible client like Oras, and Helm. Besides those clients, Harbor also provides a web portal for the administrators to easily manage and monitor all the artifacts.
Web Portal: a graphical user interface to help users manage images on the Registry
The following two examples of the Docker command illustrate the interaction between Harbor’s components.
The process of docker login
Suppose Harbor is deployed on a host with IP 192.168.1.10. A user runs the docker command to send a login request to Harbor:
$ docker login 192.168.1.10After the user enters the required credentials, the Docker client sends an HTTP GET request to the address “192.168.1.10/v2/”. The different containers of Harbor will process it according to the following steps:

(a) First, this request is received by the proxy container listening on port 80. Nginx in the container forwards the request to the Registry container at the backend.
(b) The Registry container has been configured for token-based authentication, so it returns an error code 401, notifying the Docker client to obtain a valid token from a specified URL. In Harbor, this URL points to the token service of Core Services;
(c) When the Docker client receives this error code, it sends a request to the token service URL, embedding username and password in the request header according to basic authentication of HTTP specification;
(d) After this request is sent to the proxy container via port 80, Nginx again forwards the request to the UI container according to pre-configured rules. The token service within the UI container receives the request, it decodes the request and obtains the username and password;
(e) After getting the username and password, the token service checks the database and authenticates the user by the data in the MySql database. When the token service is configured for LDAP/AD authentication, it authenticates against the external LDAP/AD server. After successful authentication, the token service returns an HTTP code that indicates success. The HTTP response body contains a token generated by a private key.
At this point, one docker login process has been completed. The Docker client saves the encoded username/password from step (c) locally in a hidden file.
The process of docker push

(We have omitted proxy forwarding steps. The figure above illustrates communication between different components during the docker push process)
After the user logs in successfully, a Docker Image is sent to Harbor via a Docker Push command:
# docker push 192.168.1.10/library/hello-world(a) Firstly, the docker client repeats the process similar to login by sending the request to the registry, and then gets back the URL of the token service;
(b) Subsequently, when contacting the token service, the Docker client provides additional information to apply for a token of the push operation on the image (library/hello-world);
(c) After receiving the request forwarded by Nginx, the token service queries the database to look up the user’s role and permissions to push the image. If the user has the proper permission, it encodes the information of the push operation and signs it with a private key and generates a token to the Docker client;
(d) After the Docker client gets the token, it sends a push request to the registry with a header containing the token. Once the Registry receives the request, it decodes the token with the public key and validates its content. The public key corresponds to the private key of the token service. If the registry finds the token valid for pushing the image, the image transferring process begins.
Harbor что за программа
Harbor 2.8 Documentation
Welcome to the Harbor 2.8.x documentation. This documentation includes all of the information that you need to install, configure, and use Harbor.
Harbor Installation and Configuration
This section describes how to install Harbor and perform the required initial configuration. These day 1 operations are performed by the Harbor Administrator. Read more
Harbor Administration
This section describes how to use and maintain your Harbor registry instance after deployment. These day 2 operations are performed by the Harbor Administrator. Read more
Working with Harbor Projects
This section describes how users with the developer, maintainer, and project administrator roles manage users, and create, configure, and participate in Harbor projects. Read more
Building, Customizing, and Contributing to Harbor
This section describes how developers can build from Harbor source code, customize their deployments, and contribute to the open-source Harbor project. Read more
Access the Documentation Source Files
The source files for this documentation set are located in the Harbor repository on Github.
For the previous versions of the docs, go to the docs folder in the Github repository and select the appropriate release-X.Y.Z branch.
Subsections
- Harbor Installation and Configuration
- Harbor Administration
- Working with Projects
- Building, Customizing, and Contributing to Harbor
Harbor v2.6.0 GA – exciting new features
Cloud-native technologies represented by Kubernetes have become the core driving force of enterprises’ digital transformation and business amplifiers. As one of the cornerstone technologies of the cloud-native ecosystem, Harbor plays an extremely important role in supporting flexible image distribution. With more and more applications and CI/CD pipelines being implemented, Harbor needs to be able to handle thousands or more requests at one time. With the increasing demand, the Harbor team has started making performance improvements to handle high request scenarios. This includes the Harbor Cache Layer which was introduced in Harbor v2.6.
Some typical user stories for Harbor include:
- As a developer/tester, I want to pull/push my business application to a registry for feature testing or bug validation.
- As an operator, I want to maintain the registry by executing some daily scan/replication/retention/gc… jobs.
- As a user, I want to deploy my applications by pulling images from the registry.
While seemingly straightforward, these scenarios can lead to the need for a highly available and performant registry as the Harbor’s integration points and user base grows, data requests are made transiently or periodically. In summary, it’s hard to evaluate the concurrency requests from the outside, so Harbor needs some adaptive and advanced modules to help to improve its performance in high utilization scenarios.
Full article can be found here and more information about the initial proposal here
CVE export:
Motivation
Kubernetes and container adoption is witnessing widespread adoption as detailed within the CNCF survey conducted in February 2022. This trend ultimately bolsters the most fundamental fact – container registries can no longer act as image stores. Instead container registries are now fundamental building blocks for the software supply chain within the cloud-native software realm and hence must expose features that allow the users to assess the software compliance of the images which are stored in the registry. One of the critical parameters for ensuring software compliance is assessing software vulnerabilities present within container images
Harbor is an open-source enterprise-grade registry that extends the Docker distribution to provide features such as image vulnerability scanning, replication and activity auditing. With the upcoming 2.6.0 release, Harbor now exposes a mechanism to export CVE vulnerabilities for images to the automation friendly CSV format. The functionality hence unlocks further visibility and control over the security posture of images and their distribution.
Feature overview
The CSV export feature can be triggered for a project by any user who has Project Admin, Developer, or Maintainer roles on the project. The user can specify one or more repositories, tags or labels as filters while triggering the export. As an additional bonus, the CSV export can be triggered using Harbor APIs thereby yielding itself to be consumed by CI/CD workflows as well as automated scanning.
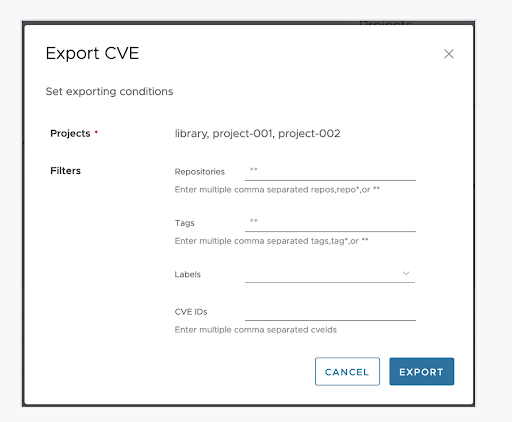
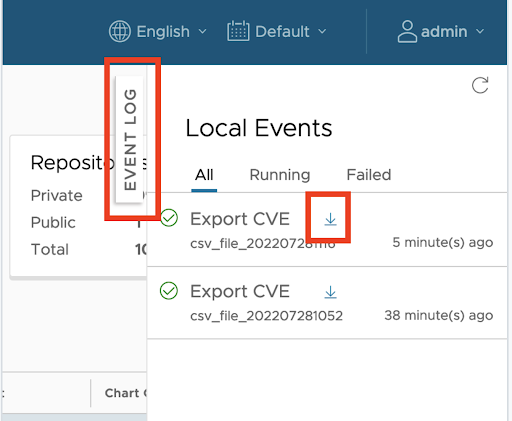
Once the export job completes, the user can download the CSV report from the Harbor UI. Once the CSV file is downloaded by the user, it is deleted from Harbor internal stores and subsequent download attempts for the same file are not possible.
Accessing CSV Export Programmatically
The CVE export of functionality adheres to the Harbor standard of providing an API access endpoint through which the functionality can be invoked by 3rd party programs, thereby facilitating automation. A programmatic access consists of the following 3 steps:
- Invoke the CVE export API
curl --location --request POST 'https://harbordev.com/api/v2.0/export/cve' \ --header 'X-Scan-Data-Type: application/vnd.security.vulnerability.report; version=1.1' \ --header 'Authorization: Basic xxx' \ --header 'Content-Type: application/json' \ --data-raw '< "labels": [ ], "repositories": "", "projects": [ ], "job_name": "Test_Vuln_Export_Job" >'The above API execution returns the execution id associated with the CSV export job. This execution id is used as a reference in further API calls to retrieve the status and download the CSV data.
- Check the status of the CVE export job.
curl --location --request GET 'https://harbordev.com/api/v2.0/export/cve/execution/35' \ --header 'X-Scan-Data-Type: Test' \ --header 'X-Harbor-CSRF-Token: xxx' \ --header 'Authorization: Basic xxx' \ --data-raw ''Note that in the above GET request the execution id of the CSV export job is specified as a part of the invocation URL. In this case the execution ID we obtained for the job was 35
- Download the CVE exported data
curl --location --request GET 'https://harbordev.com/api/v2.0/export/cve/download/35' \ --header 'X-Scan-Data-Type: Test' \ --header 'X-Harbor-CSRF-Token: xxx' \ --header 'Authorization: Basic xxx' \ --data-raw ''Once the CSV file is downloaded by the user, it is deleted from Harbor internal stores and subsequent attempts to download the same file would result in an error.
Conclusion
The CVE export functionality exposed by Harbor 2.6.0, provides a fundamental building block for auditing and controlling the CVE stature of the registry images. By providing an easy to use UI experience as well as a streamlined programmatic workflow, it opens up the numerous possibilities for integrating CVE compliance checks within the core software supply chain and ensuring that software being delivered not only caters to the business needs but is also audited and protected against vulnerabilities thereby ensuring compliance
For full information please check the Harbor v2.6.0 official documentation
Purge and Forward Audit Log
The audit_log is used to record the image pull/push/delete operations so that administrators could retrieve the history of the operation log. In a typical large Harbor server, there might be a large amount pull request and small amount of push request, delete request. Because the audit log is stored in database table, it cost of amount DB IO time and disk space to write the audit_log, it is better to provide a configurable way to log these information in either the file system or database. The audit_log table because of it is large size, it requires the DBA to create a job to clean up it periodically and it also cause the historical data cannot be retrieved. the purge and forward audit log feature provide a way to forward the audit log to external endpoint and purge the audit log table periodically.
Feature overview
The log rotation feature provide a way to configure and schedule the purge operation to the audit log table. administrators could specify the operations need to delete and how long should the audit log be kept in database. The audit log forwarding feature allow user to forward the audit log to an existing sys log endpoint, such as Wavefront LogInsight, Logstash, and once the forward setting is configured, then the administrator could disable to log audit information in database.
Purge audit log
After install Harbor 2.6.0, login to Harbor in browser, there is a new menu item named “Clean Up” under “Administration”. there are two tabs, “Garbage Collection” and “Log Rotation”
При подготовке материала использовались источники:
https://github.com/goharbor/harbor/wiki/Architecture-Overview-of-Harbor
https://goharbor.io/docs/main/
https://goharbor.io/blog/harbor-2.6/
- Authentication & Authorization