 Онлайн Радио 24
Онлайн Радио 24 FreeOCR
FreeOCR – это полностью бесплатная программа для оптического распознавания отсканированного текста в операционной системе Windows. Она поддерживает прямой импорт отсканированного текста с большинства сканеров, умеет открывать большинство многостраничных Tiff-изображений и отсканированных PDF-файлов, а также популярных форматов файлов изображений. Сохранение распознанного текста возможно как в виде простого текстового файла, так в формат Microsoft Word.
Несмотря на то, что интерфейс программы не переведен на русский язык, обилие иконок наглядно показывающих предназначение кнопок, поможет пользователям не знающим английского языка. Главное окно программы поделено на две части, в одной из которых отображается отсканированный текст, а в другой – результат распознавания. Актуальные версии программы поддерживают распознавание русского текста, однако не будем лукавить, изначально программа «заточена» на работу с английским, немецким, французским, итальянским и испанским языками.
Кстати, русский язык не входит в базовую установку программы. Для распознавания текстов на русском необходимо скачать дополнительный файл rus.traineddata, после чего в программе открыть меню Settings → Open Language Folder, скопировать файл rus.traineddata в открывшуюся папку и перезапустить программу. После этого в выпадающем списке OCR Language (языков доступных для распознавания текстов) появится русский язык (rus) .
Использование в FreeOCR новейшей версии движка распознавания Tesseract (v3.01) позволило значительно повысить точность анализа макетов страниц, что дает возможность запускать процесс распознавания без предварительного использования инструмента выделения текстовых зон.
В целом, программа очень проста в установке и использовании, а поддержка работы с многостраничными файлами в формате tiff, документами Adobe PDF и факсами, а так же большинством типов изображений, включая сжатые Tiff (которые изначально не поддерживались движком распознавания) делают её действительно универсальным инструментом. Как уже говорилось, движок может напрямую работать с большинством современных сканеров по протоколам Twain и WIA, однако сохранение отсканированных файлов возможно лишь в формат JPG. На своем официальном сайте авторы обещали включить поддержку сохранения в формат PDF, однако, учитывая, что последняя версия программы была выпущена в 2015 году, особо рассчитывать на это не приходится.
Кстати, OCR-движок Tesseract, включенный в состав программы, изначально разрабатывался в лаборатории Hewlett Packard в период с 1985 по 1995 год. На конкурсе организованном Университетом Невады в Лас-Вегасе он вошел в тройку победителей. В наше время поддержка кода движка осуществляется компанией Google, которая распространяет его под лицензией Apache V2.0. Сама же FreeOCR распространяется полностью бесплатно, вы можете применять её так как вам необходимо, включая коммерческое использование.
FreeOCR

Бесплатное программное обеспечение для оптического распознавания текста на Windows. Поддерживает сканирование с большинства сканеров в стандарте Twain, а также может открывать большинство отсканированных PDF-файлов и многостраничных изображений Tiff, а также популярных форматов файлов изображений. Может экспортировать текст формат Microsoft Word.
Добавить отзыв
Альтернативы FreeOCR
ABBYY FineReader, Tesseract OCR, Readiris
Новости и обзоры FreeOCR
2010. FreeOCR – бесплатная программа для распознавания текста на Windows
FreeOCR – это простая бесплатная OCR программы, которая может распознавать текст с документов, полученных из pdf файлов, графических файлов (поддерживаются все основные форматы) и со сканера. Все окно программы разделено на две половины, в левой стороне находится каретника с текстом которое надо распознать, а с правой, текст, результат работы программы. Программа не может автоматически разбивать страницу на колонки, или определить где именно находятся картинки, поэтому для получения нормальных результатов, ту часть изображения, которую надо распознать необходимо, выделить, зажав правую кнопку мыши. Весь текст, который распознал FreeOCR, добавляется к уже существующему в самый конец, поэтому желательно каждый раз очищать это окно, чтоб не приходилось искать какие абзацы были переведены. И главный недостаток программы – она пока не поддерживает русский язык.
Freevi
Бесплатная программа для распознавания текста FreeOCR, не дружит с русским языком
25 декабря 2010 Serg Написать комментарий К комментариям
До недавнего времени был уверен, не существует бесплатных программ для распознавания отсканировано текста, когда надо документы, книги пригнать на компьютер. Есть только монстры, вроде, популярного у нас ABBYY FineReader, за который в обязательном порядке придется выкладывать немаленькие деньги. Но, оказалось, есть бесплатные OCR (оптическое распознавание символов) программы, развитие которых поддерживают энтузиасты. Среди таких представителей, абсолютно бесплатное приложение для распознавания текста FreeOCR.
Обязательно проверьте пред началом установки, чтоб компьютер был подключен к интернету, потому-то будем запускать оболочку, которая будет скачивать все необходимые файлы, ведь установочный файл весит всего 150 кб, и туда точно невозможно поместить все необходимое для работы столь сложной программы . Разработчики предупреждают, что будут скачано дополнительно 11 мегабайт, в моем случае папка с установленной программой весит 4 Мб. В остальном стандартный перечень вопросов, в какую папку ставить и подтверждение лицензионного соглашения.
Запустив программу, неожиданно получаем простенький, но вполне современный интерфейс. Даже хотел сказать, что там есть ленточное меню, но его там нет, просто разработчикам удалось все настолько стильно и органично сделать.
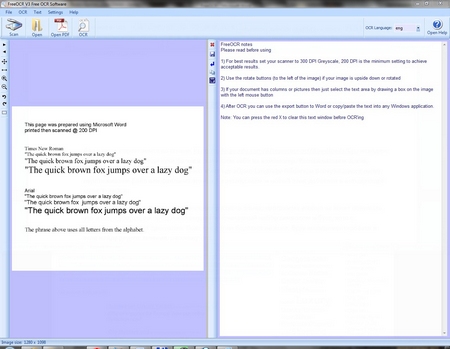
FreeOCR может распознавать текст с документов, полученных из pdf файлов (работает с ними довольно медленно и тормознуто, когда перелистываешь страницы), графических фалов (поддерживаются все основные форматы) и со сканера (жмем на кнопку, выбираем один из доступных сканеров, а дальше все на автомате, никаких настроек не предлагается). Собственно этому и посвящено меню с большими иконками, под основным, которые красноречиво расскажут о своем назначении. Кто задается вопросом, зачем нужна кнопка «OSR», собственно поле нажатия на неё и происходит распознавание текста.
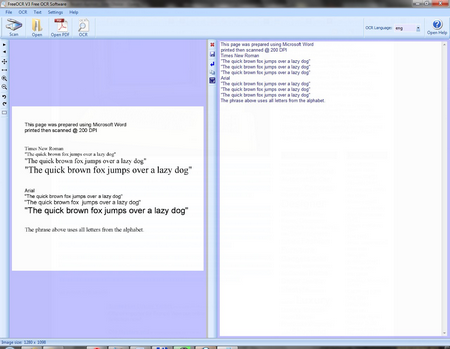
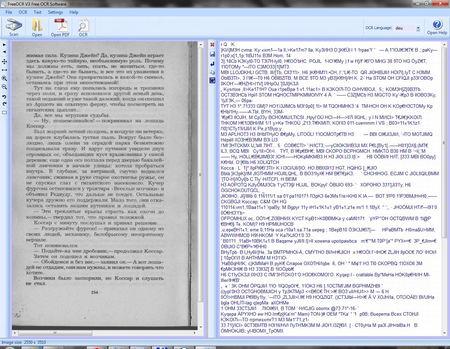
Все окно программы разделено на две половины, в левой стороне находится каретника с текстом которое надо распознать, а с правой, текст, результат работы программы.
Теперь надо рассказать о некоторых нюансах работы FreeOCR. Программа не может автоматически разбивать страницу на колонки, или определить где именно находятся картинки, поэтому для получения нормальных результатов, ту часть изображения, которую надо распознать необходимо, выделить, зажав правую кнопку мыши. На боковой панели есть несколько кнопок, которые позволяют облегчить с картинками, это зум, вращение на 90 градусов (когда текст лежит боком), и перелистывание многостраничных документов.
Весь текст, который распознал FreeOCR, добавляется к уже существующему в самый конец, поэтому желательно каждый раз очищать это окно, чтоб не приходилось искать какие абзацы были переведены. Панель иконок помогает работать с текстом, позволяет быстро стирать текст в правой панели, сохранять в готовый текст в файл, копировать в буфер обмена, убирать разметку страницы и отправлять в текстовый редактор Word (почему именно ему досталась такая честь непонятно).
Только вот с языками вышла заминка, с текстом на английском языке справляется неплохо, но вместо рисских слов выдает нечитаемый набор символов. Как оказалась, какой язык надо использовать при распознавании текста, выбираем вручную из выпадающего меню справа вверху, оно подписано «OSR Language». По умолчанию идет только английский, остальные придется добавлять отдельно.
Для начала оправляемся по ссылке http://code.google.com/p/tesseract-ocr/downloads/list, находим нужный нам язык, среди кучи фалов и скачиваем себе на компьютер. Распаковываем архив, приходим в программе в раздел меню «Settings->Open Language Folder», и в открывшуюся папку перетаскиваем файлы из архива. Перезапускаем и новый язык добавлен в выпадающее меню FreeOCR.
Только вот у меня даже после добавления русского языка, программа упорно не хочет понимать это язык, показывая, что начался процесс обработки, но без результатов, остается пустое место, не распознавания текста, хотя с английским работает прекрасно. Пока как с этим бороться не ясно, буду экспериментировать и если найду рецепт лечения, расскажу его.
Как оказалось движок Tesseract OSR (что это такое, написано ниже) который здесь используется для распознавания текста старой версии 2.04, сейчас актуальный 3.0, и в нем поддержки русского языка, только английский, немецкий, испанский, итальянский, французский и еще несколько экзотических. В общем, при всей своей перспективности, программа в нынешнем виде абсолютно бесполезна в нашей стране, пока не начнет использовать Tesseract OSR 3.0, а там нормально поддерживается русский язык. Вот именно для этой версии готова поддержка распознавания текста большого количества языков.
Настроек в программе нет, все работает в автоматическом режиме.
Теперь хочу немного рассказать, откуда появился FreeOCR. Как оказалось движок, который распознает текст, взят из открытого проекта под названием Tesseract OSR. Разработчики FreeOCR только сделали свою оболочку и все максимально автоматизировали, чтоб не дергать пользователей лишними вопросами.
При всем пессимизме пред началом работы FreeOCR, он действительно работает и оказался очень дружелюбный к пользователям. Во всем можно разобраться в течение нескольких минут. Но это касается только английского языка, который идет по умолчанию, добавление поддержку других языков, можно охарактеризовать моя борьба.
Еще есть достаточно серьезные недостатки, это не уверенное распознавание символов, слишком много возникает ошибок, потом приходиться тратить время на проверку правописания и все перечитывать. Но сама главное это поддержка малого количества языков, русский не входит в список избранных. В нынешнем состоянии не рекомендую использовать. Хотя кто работает с документами на английском языке, может стать неплохим выбором, ведь можно бесплатно использовать даже в коммерческих организациях.
Прекрасно работает в 32-х и 64-х битных операционных системах. Интерфейс программы только на английском языке, но пунктов и надписей немного поэтому не составит труда разобраться.
Сайт для бесплатного скачивания FreeOCR http://www.paperfile.net/
Последняя версия на момент написания FreeOCR 3.0
Размер программы: установочный файл 156 Кб
Совместимость: Windows Vista и 7, Windows Xp
При подготовке материала использовались источники:
https://soft.mydiv.net/win/download-FreeOCR.html
https://www.livebusiness.org/tool/4282/
https://freevi.net/besplatnaya-programma-dlya-raspoznavaniya-teksta-freeocr-ne-druzhit-s-russkim-yazykom/