 Онлайн Радио 24
Онлайн Радио 24 2 для чего предназначены программы оптического распознавания документов
Первые системы оптического распознавания символов появились практически одновременно с первыми компьютерами. В 50-х годах прошлого столетия с помощью коммерческих OCR системы начали обрабатывать отчеты о продажах, набранные на печатной машинке, и переводили их в перфокарты. С тех пор OCR пережил много изменений, главным из которых стала замена применяемых в алгоритмах распознавания разнообразных классификаторов символов искусственными нейронными сетями (ИНС, ANN).
Вызовы современных OCR технологий
Сейчас технологиям распознавания брошен серьезный вызов, когда все чаще речь идет о распознавании изображений с камер мобильных устройств или обычных веб-камер. Это могут фотографии или кадры из видеопотока. Чтобы лучше понять сложность поставленной задачи, давайте начнем с примера. Изображение документа для распознавания можно получить разными способами, и мы выбрали три из них:
1) взяли Canon CanoScan LiDE 300, отсканировали документ с разрешением 300dpi и бинаризовали результат;
2) сфотографировали документ на iPhone 11 при комнатном освещении;
3) сняли видео веб-камерой и взяли из него один кадр.
Как видно на картинке, системы распознавания в наши дни должны быть устойчивы к самым разнообразным условиям съемки. Очевидно, качество изображений может существенно различаться.
| Binarized scan | 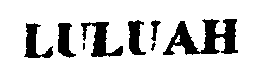 |
| Photo with iPhone 11 | 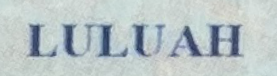 |
| Web camera video frame |  |
Вот так может выглядеть рабочий процесс системы оптического распознавания.

Большинство подходов начинаются с предобработки изображения, которая, как правило, включает бинаризацию изображение для упрощения последующей сегментации на символы. Алгоритм сегментации делит изображение строки на изображения отдельных символов, которые подаются классификатору. Иногда, для улучшения качества распознавания к результату классификации могут применяться алгоритмы постобработки.
В случае mobile optical character recognition или мобильного OCR (на Android, iOS или иных системах), или же распознавания на мобильном устройстве, возникают две трудности: ограничения на вычислительные мощности и неконтролируемые условия съемки. При работе с персональными документами, банковскими бумагами или, например, результатами теста на COVID-19 важно обеспечить максимум конфиденциальности и минимизировать риск утечки данных, так что распознавание “в облаке” сразу отпадает. Распознавание непосредственно на устройстве накладывает ограничения на вычислительную сложность алгоритмов, ведь система должна работать быстро и энергоэффективно. С другой стороны, меньшие ограничения на условия съемки значительно расширяют диапазон возможных искажений. Появляются проективные искажения, смазывание, перепады яркости, блики и многое другое. Все это существенно влияет на этап предобработки.
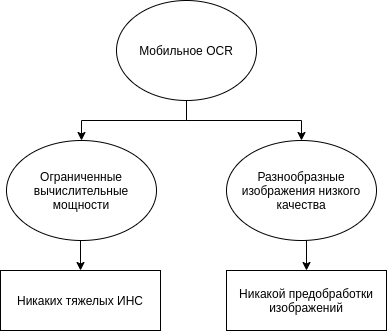
В результате при мобильном распознавании, с одной стороны, возникает множество ошибок у стандартных подходов к сегментации, а с другой – из-за ограничения на вычислительные ресурсы многие современные нейросетевые модели, например, рекуррентные сети (RNN) или LSTM-сети становятся неэффективными или же излишне ресурсозатратными. Таким образом, для успешного распознавания изображений, снятых на камеры мобильных устройств (работающих на Android или iOS), необходимо придумывать абсолютно новые алгоритмы и переосмысливать уже известные подходы.
Примером переосмысления старых подходов можно считать замену алгоритмов сегментации, основанных на обработке изображений, на сегментирующие нейронные сети, как это уже когда-то произошло с классификаторами. Наиболее многообещающей моделью для такие подходов представляется полносверточная сеть (fully convolutional network, FCN).

Замена отдельного изображения на видеопоток приводит к появлению концепции 4D OCR и новым возможностям распознавания, прежде всего, к алгоритмам межкадровой интеграции результатов распознавания. Более того, при обработке видео можно рассматривать процесс распознавания как anytime алгоритм, готовый в любой момент дать ответ. Выбор оптимального числа кадров можно осуществлять, решая задачу остановки.
В каких процессах применяются системы оптического распознавания (OCR)
Давайте приведем несколько примеров. Все ниже перечисленные процессы можно улучшить и ускорить с помощью OCR системы.
Платежи и переводы могут стать гораздо быстрее с добавлением распознавания банковской карты. Замена ручного ввода данных на сканирование QR, AZTEC, PDF 417 или другого типа штрихкода вместе с распознаванием карты поможет избежать раздражающих ошибок во введенных данных и улучшить впечатление конечного пользователя от банковского приложения, онлайн-магазина или даже офлайн магазина.
При продаже билетов и регистрации на рейс пассажирам требуется вводить свои личные данные. Автоматическое сканирование МЧЗ (машиночитаемой зоны) или паспорта позволит сделать эти процессы более удобными для пользователей и минимизировать число ошибок в данных.
Удаленная идентификация клиента – популярная и крайне важная опция для многих задач, включая проверку возраста, онлайн-регистрацию, активацию сим-карты, бронирование номеров в отелях и предварительную запись на медицинские услуги. С ее помощью можно упростить жизнь пользователю, а также оптимизировать работу персонала и в результате избежать очередей в офисах, магазинах, фойе отелей и других местах скопления людей.
Отдельно стоит выделить банковские услуги, где применение OCR для распознавания документов и удостоверений личности является must-have функцией. В этой сфере любые ошибки в данных приводят к проблемам для клиентов, оставляя у них плохое впечатление от банка и влияя на решение о дальнейшем обслуживании. Встроенное распознавание ID карт, паспортов, водительских прав и других документов ускоряет процесс открытия счета новым клиентам, упрощает аутентификацию текущих клиентов и предоставляет возможности развития кросс-продаж.
А что об общедоступных OCR решениях?
В наше время существует много общедоступных open-source распознавателей текста. Такие решения могут быть очень полезны в образовательных целях или для учебного демонстрационного приложения. Однако они могут быть не просто бесполезны, а опасны для настоящих “боевых” коммерческих систем. При этом, их существенным недостатком окажется не только точность и скорость распознавания, но и уязвимость для внешних атак.
Атаки на нейронные сети – это популярная тема для научных исследований. Главные типы атак – отправление данных и атака уклонением с помощью состязательных примеров. При отравлении данных ошибки вводятся в сеть на этапе обучения. А при применении сети распознаватель может совершить специфические серьезные ошибки. Единственный способ избежать такой атаки – быть уверенными в своих данных. А как можно быть уверенным в данных, которых вы никогда не видели? При атаке уклонением злоумышленник пытается заставить сеть дать неверный ответ. Иногда он даже может предопределить этот ответ. Для открытых систем оптического распознавания текста и символов (OCR) такие примеры можно посчитать, так как эти системы общедоступны. Можно просто скачать модель и подобрать нужные примеры.
Теперь чуть больше об OCR сервисах Smart Engines
В Smart Engines мы разрабатываем OCR решения, которые могут работать с изображениям, фотографиями, сканами или видеопотоком в реальном времени. Условия съемки могут быть самыми разными – не нужно специально фокусировать камеру или же искать хорошо освещенное место. Наше ПО работает автономно на конечном устройстве, никуда не передает данные клиента, не хранит их и не требует интернет-соединения. При разработке нашего OCR модуля мы активно пользуемся генерацией искусственных данных и не используем предобученные модели. Таким образом, наше решение оказывается гораздо более устойчивым для внешних атак.
Программные продукты Smart Engines, в которых мы применяем собственные технологии OCR
– Smart ID Engine – SDK для сканирования более чем 2427 типов удостоверяющих личность документов со всего мира, напечатанных с использованием латиницы, кириллицы, арабицы и других письменностей;
– Smart Code Engine – решение для распознавания банковских карт, одномерных и двумерных штрихкодов, МЧЗ и других кодированных объектов;
– Smart Document Engine – система автоматического анализа и распознавания деловых документов, форм и анкет.
– Сканеры Smart Engines – программно-аппаратные комплексы для распознавания и проверки подлинности паспортов и других удостоверений личности
Тема № 2 системы оптического распознавания информации
В практической деятельности часто встречаются ситуации, когда необходимо перевести в электронный вид документ, напечатанный на бумаге. В этом случае можно просто набрать документ на компьютере, что довольно трудно, либо воспользоваться сканером – устройством, специально предназначенным для перевода документов в электронный вид. Для организации сканирования изображения помимо непосредственно сканера требуется одна из специальных программ систем оптического распознавания текста.
Системы оптического распознавания текста (Optikal Character Recognition – OCR – системы) предназначены для автоматического вода печатных документов в компьютер.
Современные программы распознавания текста не только ошибаются реже, чем живой человек, но и обеспечивают проверку орфографии, автоматическое форматирование текста и массу других дополнительных удобств.
Последние годы ведущие позиции на российском рынке «распознавалок» удерживают программы FineReader и CuneiForm. Несмотря на свои замысловатые названия, обе программы отечественного производства вполне хорошего качества. По своим возможностям и сервису они примерно равноценны.
Главное окно программы FINEREADER
Программа относительно проста в использовании (особенно если учесть сложность выполняемой ею задачи). Отключаемые панели инструментов снабжены сплывающими подсказками, информативная строка состояния поясняет назначение всех элементов управления, имеется мощная справочная система.
После запуска программы FineReader (Пуск/программы/ABBYY FineReader) открывается Главное окно (рис.1.) программы.
В верхней части Главного окна находится меню системы, под ним – панели инструментов. В программе их 4: Стандартное, Форматирование, Изображение и SCAN & READ. Спрятать или показать инструментальные панели можно через меню Вид/Панели инструментов или через локальное меню, которое открывается щелчком правой кнопки мыши на одной из инструментальных панелей. Панелей, которые видны на экране, будут отмечены галочкой.
Внизу окна расположена информационная панель, которую называют так же строкой состояния. Она отражает информацию о состоянии программы и производимых ею операциях, а так же краткую справку о выбираемых пунктах меню и кнопках.
Остальное пространство Главного окна занимают по мере своего появления рабочие окна программы: Пакет, Изображение, Крупный план и Текст.
В окне Крупный план по умолчанию показывается черно-белое изображение не зависимо от того, какое именно изображение имеет оригинал – цветное, серое или черно- белое. Если ваше изображение цветное, и вы хотите, чтоб показываемое в окне Крупный план изображение так же было цветным, следует изменить настройки. Для этого в окне Опции (меню Сервис/ Опции) на вкладке Вид снимите отметку с пункта Черно-белая палитра в окне Крупный план (рис. 3).
КАК ВВЕСТИ ДОКУМЕНТ ЗА ОДНУ МИНУТУ
Перед началом сканирования необходимо включить сканер, если он имеет отдельный от компьютера источник питания, включить компьютер и запустить программу FineReader. Перед вами откроется окно программы. Вставьте в сканер страницу, которую вы хотите распознать, нажмите на стрелку справа от кнопки SCAN & READ, в открывшемся меню выберите пункт Мастер SCAN & READ.
Программа вызывает специальный режим Мастер SCAN & READ, при котором весь процесс сканирования сопровождается подсказами системы (рис 4). Мастер SCAN & READ позволяет отсканировать и распознать страницу или открыть и распознать графическое изображение. При работе с мастером следует выполнять его указания.
6.4. Системы распознавания текстов (ocr-системы). Характеристика и функциональные возможности.
С помощью сканера достаточно просто получить изображение страницы текста в графическом файле. Однако работать с таким текстом невозможно: как любое сканированное изображение, страница с текстом представляет собой графический файл – обычную картинку. Текст можно будет читать, распечатывать, но нельзя будет его редактировать и форматировать. Для получения документа в формате текстового файла необходимо провести распознавание текста, то есть преобразовать элементы графического изображения в последовательности текстовых символов.
Основным методом перевода бумажных документов в электронную форму является сканирование. В результате сканирования получается графическое изображение, состоящее из точек, т.е. растровое изображение. Количество точек определяется как размером изображения, так и разрешением сканера.
Графический образ, получаемый после сканирования документа, иногда необходимо перевести в текст. Для этого используются специальные программные средства, называемые средствами распознавания образов. Из программ, способных распознавать текст на русском языке наиболее известной являетсяABBYY Fine Reader.
Преобразование документа в электронный вид происходит в три основных этапа. Каждый из этих этапов может выполняться программами как автоматически, так и под контролем пользователя.
- Сканирование. Запускается сканирующий модуль, настраиваются параметры сканирования (разрешение, размер, тип сканирования) и происходит собственно сканирование.
- Сегментация и распознавание текста. Прежде чем получить готовый текст, необходимо разбить фрагменты документа на блоки (текст, рисунок, таблица и т.д.), для того, чтобы правильно их распознать (преобразовать в текстовый документ).
- Проверка орфографии и передача текстового документа в нужное приложение для дальнейшей работы или сохранение в файл.
- Если исходный документ имеет типографское качество, то задача распознавания решается методом сравнения с растровым шаблоном.
- При распознавании документов с низким качеством печати используется метод распознавания символов по наличиюв нихопределенных структурных элементов(отрезков, колец, дуг и др.).
- Планшетные–наиболее распространённые, поскольку обеспечивают максимальное удобство для пользователя – высокое качество и приемлемую скорость сканирования. Представляет собой планшет, внутри которого под прозрачным стеклом расположен механизм сканирования.
- Барабанные– применяются в полиграфии, имеют большое разрешение (около 10 тысяч точек на дюйм). Оригинал располагается на внутренней или внешней стенке прозрачного цилиндра (барабана).
- Ручные– в них отсутствует двигатель, следовательно, объект приходится сканировать вручную, единственным его плюсом является дешевизна и мобильность, при этом он имеет массу недостатков – низкое разрешение, малую скорость работы, узкая полоса сканирования, возможны перекосы изображения, поскольку пользователю будет трудно перемещать сканер с постоянной скоростью.
- Сканеры штрих-кода– небольшие, компактные модели для сканирования штрих-кодов товара в магазинах.
- распознавание текста;
- все найденные программой ошибки выделяются цветом. Затем программа производит проверку текста на наличие орфографических ошибок, и все некорректные слова подчеркивает красными линиями. Обнаруженные изображения программа выделяет красным цветом и в дальнейшем их не обрабатывает, а оставляет их такими, какие они есть, соответственно и передает их такими, как они получились при сканировании.
- Редактирование полученного документа.
При подготовке материала использовались источники:
https://studfile.net/preview/4258934/page:2/
https://studfile.net/preview/5407066/page:27/