 Онлайн Радио 24
Онлайн Радио 24 Машинное обучение для рекомендательных систем – Часть 1 (алгоритмы, оценка и холодный старт)
Рекомендательные системы – одно из самых успешных и широко применяемых технологий машинного обучения в бизнесе. В листе ожидания было много людей, которые не смогли присутствовать на нашем выступлении MLMU, поэтому я делюсь слайдами и комментариями здесь.
Вы можете применять рекомендательные системы в сценариях, когда многие пользователи взаимодействуют со многими элементами.
Вы можете найти крупномасштабные рекомендательные системы в розничной торговле, видео по запросу или потоковой передаче музыки. Для разработки и сопровождения таких систем компании обычно требуется группа дорогих специалистов по анализу данных и инженеров. Вот почему даже такие крупные корпорации, как BBC, решили передать свои рекомендательные услуги на аутсорсинг.
Наша компания Recombee находится в Праге и разрабатывает универсальный автоматизированный механизм рекомендаций, способный адаптироваться к потребностям бизнеса во многих областях. Наш движок используют сотни компаний по всему миру.
Удивительно, но рекомендация новостей или видео для СМИ, рекомендация продукта или персонализация в путешествиях и розничной торговле могут обрабатываться с помощью аналогичных алгоритмов машинного обучения. Кроме того, эти алгоритмы можно настроить, используя наш специальный язык запросов в каждом запросе рекомендации.
Алгоритмы
Алгоритмы машинного обучения в рекомендательных системах обычно подразделяются на две категории – методы фильтрации на основе контента и методы совместной фильтрации, хотя современные рекомендатели сочетают оба подхода. Методы, основанные на содержании, основаны на схожести атрибутов элементов, а совместные методы рассчитывают сходство на основе взаимодействий. Ниже мы обсуждаем в основном совместные методы, позволяющие пользователям открывать новый контент, отличный от элементов, просматриваемых в прошлом.
Совместные методы работают с матрицей взаимодействия, которую также можно назвать рейтинговой матрицей в том редком случае, когда пользователи предоставляют явную оценку элементов. Задача машинного обучения – изучить функцию, которая предсказывает полезность предметов для каждого пользователя. Матрица обычно огромна, очень разрежена, и большинство значений отсутствует.
Простейший алгоритм вычисляет косинус или корреляционное подобие строк (пользователей) или столбцов (элементов) и рекомендует элементы, которые понравились k ближайшим соседям.
Методы, основанные на матричной факторизации, пытаются уменьшить размерность матрицы взаимодействия и аппроксимировать ее двумя или более маленькими матрицами с k скрытыми компонентами.
Умножая соответствующую строку и столбец, вы прогнозируете рейтинг элемента пользователем. Ошибка обучения может быть получена путем сравнения непустых оценок с прогнозируемыми. Также можно упорядочить потери при обучении, добавив штрафной член, сохраняющий низкие значения скрытых векторов.
Наиболее популярным алгоритмом обучения является стохастический градиентный спуск, минимизирующий потери за счет обновления градиента как столбцов, так и строк матриц p a q.
В качестве альтернативы можно использовать метод альтернативных наименьших квадратов, который итеративно оптимизирует матрицу p и матрицу q с помощью общего шага наименьших квадратов.
Правила ассоциации также можно использовать для рекомендации. Элементы, которые часто потребляются вместе, связаны ребром в графе. Вы можете увидеть кластеры бестселлеров (тесно связанные элементы, с которыми взаимодействовали почти все) и небольшие отдельные кластеры нишевого контента.
Правила, извлеченные из матрицы взаимодействия, должны иметь хотя бы минимальную поддержку и уверенность. Поддержка связана с частотой появления – значение бестселлеров пользуется большой поддержкой. Высокая уверенность означает, что правила не часто нарушаются.
Правила майнинга не очень масштабируемы. Алгоритм APRIORI исследует пространство состояний возможных частых наборов элементов и удаляет нечастые ветви пространства поиска.
Частые наборы элементов используются для создания правил, и эти правила генерируют рекомендации.
В качестве примера мы показываем правила, извлеченные из банковских транзакций в Чешской Республике. Узлы (взаимодействия) – это терминалы, а ребра – частые транзакции. Вы можете порекомендовать банковские терминалы, которые актуальны на основе прошлых выплат / выплат.
Наказание за популярные элементы и извлечение правил с длинным хвостом при более низкой поддержке приводит к интересным правилам, которые разнообразят рекомендации и помогают открывать новый контент.
Матрица рейтингов также может быть сжата нейронной сетью. Так называемый автоэнкодер очень похож на матричную факторизацию. Глубокие автоэнкодеры с несколькими скрытыми слоями и нелинейностями более эффективны, но их труднее обучить. Нейронная сеть также может использоваться для предварительной обработки атрибутов элементов, чтобы мы могли комбинировать подходы, основанные на содержании, и совместные подходы.
Псевдокод рекомендаций User-KNN top N приведен выше.
Правила ассоциаций могут быть добыты множеством разных алгоритмов. Здесь мы показываем псевдокод рекомендаций Best-Rule.
Псевдокод матричной факторизации приведен выше.
При совместном глубоком обучении вы тренируете матричную факторизацию одновременно с автокодировщиком, включающим атрибуты элементов. Конечно, есть еще много алгоритмов, которые вы можете использовать для рекомендации, и в следующей части презентации представлены некоторые методы, основанные на глубоком обучении и обучении с подкреплением.
Оценка рекомендателей
Рекомендации можно оценивать так же, как классические модели машинного обучения на исторических данных (автономная оценка).
Взаимодействия случайно выбранных тестирующих пользователей проходят перекрестную проверку для оценки эффективности рекомендателя по невидимым рейтингам.
Среднеквадратичная ошибка (RMSE) по-прежнему широко используется, несмотря на то, что многие исследования показали, что RMSE является плохой оценкой онлайн-производительности.
Более практичная мера автономной оценки – это отзыв или точность оценки процента правильно рекомендованных элементов (из рекомендуемых или соответствующих элементов). DCG также принимает во внимание позицию, предполагая, что релевантность элементов логарифмически уменьшается.
Можно использовать дополнительную меру, которая не очень чувствительна к смещению офлайн-данных. Покрытие каталога вместе с отзывом или точностью можно использовать для многокритериальной оптимизации. Мы ввели параметры регуляризации во все алгоритмы, позволяющие манипулировать их пластичностью и наказывать рекомендацию популярных элементов.
Как отзыв, так и охват должны быть максимальными, поэтому мы направляем рекомендации в направлении точных и разнообразных рекомендаций, позволяющих пользователям исследовать новый контент.
Холодный старт и рекомендации, основанные на содержании
Иногда взаимодействия отсутствуют. Продукты с холодным запуском или пользователи с холодным запуском не имеют достаточного количества взаимодействий для надежного измерения схожести их взаимодействий, поэтому методы совместной фильтрации не дают рекомендаций.
Проблема холодного запуска может быть уменьшена, если принять во внимание сходство атрибутов. Вы можете закодировать атрибуты в двоичный вектор и передать его рекомендателю.
Элементы, сгруппированные на основе их взаимодействия и сходства атрибутов, часто выравниваются.
Вы можете использовать нейронную сеть для прогнозирования сходства взаимодействий на основе сходства атрибутов и наоборот.
Есть еще много подходов, позволяющих уменьшить проблему холодного запуска и повысить качество рекомендаций. Во второй части нашего выступления мы обсудили методы рекомендаций на основе сеансов, глубокие рекомендации, алгоритмы объединения и AutoML, который позволяет нам запускать и оптимизировать тысячи различных алгоритмов рекомендаций в производственной среде.
Перейдите ко второй части презентации, посвященной глубоким рекомендациям, прогнозированию последовательности, AutoML и обучению с подкреплением в рекомендациях.
Алгоритм AdaBoost – Руководство по усилению алгоритмов в машинном обучении

Алгоритм AdaBoost может быть использован для повышения производительности любого алгоритма машинного обучения. Машинное обучение стало мощным инструментом, который может делать прогнозы на основе большого количества данных. Это стало настолько популярным в последнее время, что применение машинного обучения можно найти в нашей повседневной деятельности. Типичным примером этого является получение предложений для продуктов при совершении покупок в Интернете на основе прошлых товаров, купленных клиентом. Машинное обучение, часто называемое прогнозным анализом или прогнозным моделированием, может быть определено как способность компьютеров обучаться без явного программирования. Он использует запрограммированные алгоритмы для анализа входных данных, чтобы предсказать выходные данные в приемлемом диапазоне.
Что такое алгоритм AdaBoost?
В машинном обучении повышение произошло из вопроса о том, можно ли преобразовать набор слабых классификаторов в сильный классификатор. Слабый ученик или классификатор – это ученик, который лучше, чем случайные догадки, и он будет надежным в переопределении, как в большом наборе слабых классификаторов, причем каждый слабый классификатор лучше случайного. В качестве слабого классификатора обычно используется простой порог для одного признака. Если функция выше порога, чем прогнозировалось, она принадлежит положительному, в противном случае – отрицательному.
AdaBoost означает «адаптивное повышение», которое превращает слабых учеников или предикторов в сильных предикторов для решения задач классификации.
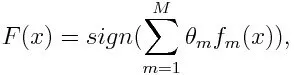
Для классификации окончательное уравнение можно поставить так:
Здесь f m обозначает m- й слабый классификатор, а m обозначает соответствующий ему вес.
Как работает алгоритм AdaBoost?
AdaBoost может быть использован для повышения производительности алгоритмов машинного обучения. Он лучше всего используется для слабых учеников, и эти модели достигают более высокой точности, чем случайный случай, при решении задачи классификации. Общие алгоритмы с AdaBoost – это деревья решений первого уровня. Слабый ученик – это классификатор или предиктор, который относительно плохо работает с точки зрения точности. Кроме того, можно подразумевать, что слабых учеников просто вычислить, и многие экземпляры алгоритмов объединяются для создания сильного классификатора посредством повышения.
Если мы возьмем набор данных, содержащий п количество точек, и рассмотрим ниже
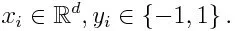
-1 обозначает отрицательный класс, а 1 обозначает положительный. Инициализируется, как показано ниже, вес для каждой точки данных как:
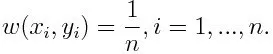
Если мы рассмотрим итерацию от 1 до M для m, мы получим следующее выражение:
Во-первых, мы должны выбрать слабый классификатор с наименьшей взвешенной ошибкой классификации, подгоняя слабые классификаторы к набору данных.
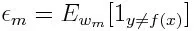
Затем вычисляем вес для m- го слабого классификатора, как показано ниже:
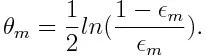
Вес является положительным для любого классификатора с точностью выше 50%. Вес становится больше, если классификатор более точен, и становится отрицательным, если точность классификатора составляет менее 50%. Прогноз может быть объединен путем инвертирования знака. Путем инверсии знака прогноза классификатор с точностью до 40% может быть преобразован в точность с 60%. Таким образом, классификатор способствует окончательному прогнозированию, даже если он работает хуже, чем случайные предположения. Тем не менее, окончательный прогноз не будет иметь никакого вклада или получить информацию от классификатора с точностью до 50%. Экспоненциальный член в числителе всегда больше 1 для неправильно классифицированного случая из положительно взвешенного классификатора. После итерации неправильно классифицированные случаи обновляются с большими весами. Отрицательно взвешенные классификаторы ведут себя так же. Но есть разница, что после того, как знак перевернут; правильные классификации первоначально превратятся в неправильную классификацию. Окончательный прогноз можно рассчитать с учетом каждого классификатора, а затем выполнить сумму их взвешенного прогнозирования.
Обновление веса для каждой точки данных, как показано ниже:
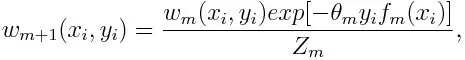
Z m здесь коэффициент нормализации. Это гарантирует, что общая сумма всех весов экземпляра станет равной 1.
Для чего используется алгоритм AdaBoost?
AdaBoost можно использовать для обнаружения лиц, так как он кажется стандартным алгоритмом обнаружения лиц на изображениях. Он использует каскад отклонения, состоящий из множества слоев классификаторов. Когда окно обнаружения не распознается на каком-либо слое как лицо, оно отклоняется. Первый классификатор в окне отбрасывает отрицательное окно, сводя вычислительные затраты к минимуму. Хотя AdaBoost сочетает в себе слабые классификаторы, принципы AdaBoost также используются для поиска лучших функций для использования на каждом уровне каскада.
Плюсы и минусы алгоритма AdaBoost
Одним из многих преимуществ алгоритма AdaBoost является его быстрота, простота и легкость в программировании. Кроме того, он обладает гибкостью, которую можно комбинировать с любым алгоритмом машинного обучения, и нет необходимости настраивать параметры, кроме T. Он был расширен для изучения проблем, выходящих за рамки двоичной классификации, и он универсален, поскольку его можно использовать с текстовым или числовым данные.
AdaBoost также имеет несколько недостатков, таких как эмпирические данные и особенно уязвим для равномерного шума. Слабые классификаторы, являющиеся слишком слабыми, могут привести к низкой марже и переоснащению.
Пример алгоритма AdaBoost
Мы можем рассмотреть пример поступления студентов в университет, где они будут либо приняты, либо от них отказано. Здесь количественные и качественные данные можно найти с разных сторон. Например, результат приема, который может быть да / нет, может быть количественным, тогда как любая другая область, такая как навыки или хобби студентов, может быть качественной. Мы можем легко придумать правильную классификацию обучающих данных с большей вероятностью, чем шанс для условий, например, если ученик хорошо разбирается в конкретном предмете, то он / она допускается. Но трудно найти очень точный прогноз, и тогда слабые ученики входят в картину.
Вывод
AdaBoost помогает в выборе обучающего набора для каждого нового классификатора, который обучается на основе результатов предыдущего классификатора. Также при объединении результатов; он определяет, какой вес следует придать каждому предложенному классификатору ответу. Он объединяет слабых учеников, чтобы создать сильного ученика для исправления ошибок классификации, что также является первым успешным алгоритмом повышения для задач двоичной классификации.
Рекомендуемые статьи
Это было руководство по алгоритму AdaBoost. Здесь мы обсудили концепцию, использование, работу, плюсы и минусы с примером. Вы также можете просмотреть наши другие Предлагаемые статьи, чтобы узнать больше –
- Наивный байесовский алгоритм
- Интервью по маркетингу в социальных сетях
- Стратегии построения ссылок
- Маркетинговая платформа в социальных сетях
Памятка по алгоритмам машинного обучения при работе с конструктором Машинного обучения Azure
Памятка по алгоритмам Машинного обучения Azure поможет выбрать в конструкторе правильный алгоритм для модели прогнозирования.
Designer поддерживает два типа компонентов: классические предварительно созданные компоненты (версия 1) и пользовательские компоненты (версия 2). Эти два типа компонентов НЕ совместимы.
Классические предварительно созданные компоненты предоставляют предварительно созданные компоненты в основном для обработки данных и традиционных задач машинного обучения, таких как регрессия и классификация. Этот тип компонента по-прежнему поддерживается, но новые компоненты добавляться не будут.
Пользовательские компоненты позволяют создать оболочку для собственного кода в качестве компонента. Она поддерживает совместное использование компонентов в рабочих областях и удобную разработку в интерфейсах Studio, CLI версии 2 и ПАКЕТА SDK версии 2.
Для новых проектов настоятельно рекомендуется использовать настраиваемый компонент, который совместим с AzureML версии 2 и будет продолжать получать новые обновления.
Эта статья относится к классическим предварительно созданным компонентам и несовместима с CLI версии 2 и пакетом SDK версии 2.
Машинное обучение Azure имеет большую библиотеку алгоритмов из семейств классификации, рекомендательных систем, кластеризации, обнаружения аномалий, регрессии и анализа текста. Каждое семейство предназначено для решения определенного типа проблем, связанных с машинным обучением.
Дополнительные сведения см. в статье Выбор алгоритмов.
Скачивание памятки по алгоритмам Машинного обучения Microsoft Azure
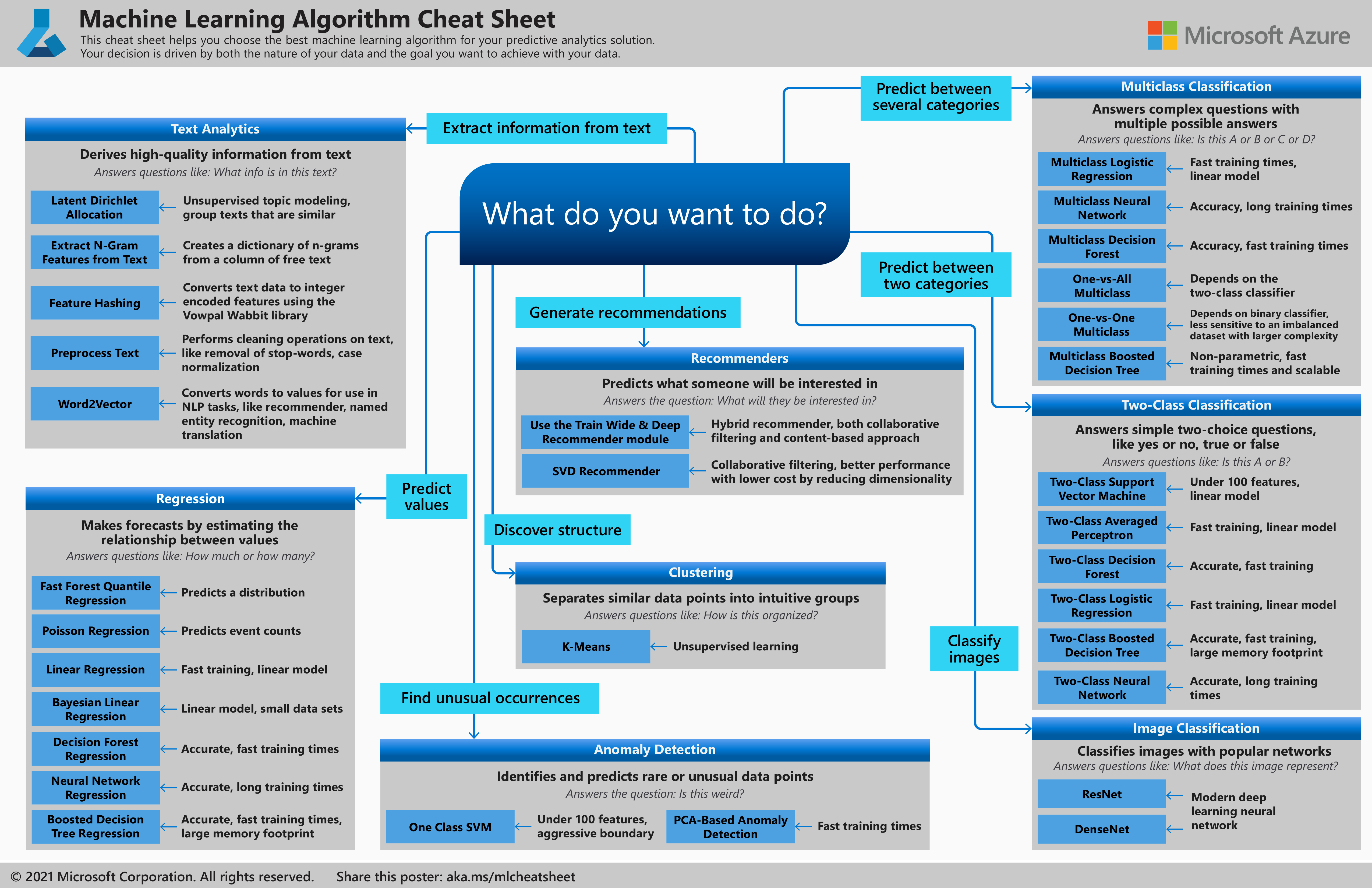
Скачайте и распечатайте памятку по алгоритмам машинного обучения размером 27,94 x 43,18 см (примерно A3), чтобы вы всегда могли обратиться к ней при выборе алгоритма.
Использование памятки по алгоритмам машинного обучения
Рекомендации, предлагаемые в этой памятке алгоритмов, представляют собой общие правила. Некоторые можно приспособить к конкретной ситуации, а некоторые можно грубо нарушать. Эта памятка предназначена для начала работы. Не бойтесь использовать несколько алгоритмов одновременно при обработке данных. Вам просто нужно понять принцип действия каждого алгоритма, а также систему, создающую данные.
Каждому алгоритму машинного обучения присущ собственный стиль индуктивного смещения. Для решения конкретной проблемы могут подходить несколько алгоритмов, но один из них может подходить лучше других. Но не всегда можно узнать заранее, какой именно подходит лучше. В подобных случаях в памятке указано сразу несколько алгоритмов. Лучше всего будет использовать один алгоритм, и если результаты неудовлетворительные, применить другие алгоритмы.
Дополнительные сведения об алгоритмах в конструкторе машинного обучения Azure см. в Справочнике по алгоритмам и компонентам.
Виды машинного обучения
Существуют три основные категории машинного обучения: контролируемое, неконтролируемое и обучение с подкреплением.
Контролируемое обучение
В контролируемом обучении каждая точка данных помечается или привязывается к интересующей категории или значению. Пример категориальной метки — назначение изображению значения cat или dog. Пример метки значения — цена продажи, связанная с подержанным автомобилем. Цель контролируемого обучения заключается в изучении множества помеченных таким образом примеров, а затем в возможности прогнозирования будущих точек данных. Например, чтобы правильно определить животных для новых фотографий или назначить точные цены продажи для других подержанных автомобилей. Это популярный и полезный тип машинного обучения.
Неконтролируемое обучение
При неконтролируемом обучении точкам данных не присваиваются метки. Вместо этого цель алгоритма неконтролируемого обучения — определенное упорядочивание данных или описание их структуры. Неконтролируемое обучение группирует данные в кластеры, как при использовании метода K-means, или находит разные способы просмотра сложных данных, чтобы они казались более простыми.
Обучение с подкреплением
В обучении с подкреплением алгоритм выбирает действие в ответ на каждую точку данных. Это наиболее распространенный подход в робототехнике, где набор показаний датчиков в один момент времени представляет собой точку данных, а алгоритму необходимо выбрать следующее действие робота. Кроме того, он естественным образом подходит для приложений из Интернета вещей. Алгоритм обучения также вскоре получает сигнал, оповещающий об успехе, который дает понять, насколько удачно было принято решение. На основе этого сигнала алгоритм изменяет свою стратегию для достижения лучшего результата.
Дальнейшие действия
- Дополнительные сведения см. в статье Выбор алгоритмов
- Сведения о студии при использовании Машинного обучения Azure и портала Azure.
- Учебник. Создание модели прогнозирования в конструкторе Машинного обучения Azure.
- Сравнение глубокого и машинного обучения.
При подготовке материала использовались источники:
https://questu.ru/articles/432154/
https://ru.education-wiki.com/1138545-adaboost-algorithm
https://learn.microsoft.com/ru-ru/azure/machine-learning/algorithm-cheat-sheet?WT.mc_id=docs-article-lazzeri&view=azureml-api-1&viewFallbackFrom=azureml-api-2