 Онлайн Радио 24
Онлайн Радио 24 Создание приложения для анализа данных машинного обучения
Нейронные сети очень мощны для выполнения предиктивного анализа и решения аналитических задач. Они широко используются для классификации данных, чтобы обнаруживать закономерности и делать прогнозы. Бизнес-кейсы варьируются от классификации и защиты данных клиентов до классификации текста, поведения потребителей и многих других задач.
Чтобы показать, как создать приложение для выполнения анализа данных для решения задач классификации, команда Windows ML создала руководство «Анализ данных с помощью Pytorch и машинного обучения Windows». В этом руководстве показано, как обучить модель нейронной сети на основе табличного набора данных с помощью библиотеки PyTorch и как развернуть эту модель в приложении машинного обучения Windows, которое может работать на любом устройстве Windows.
Хотя в этом руководстве используется набор данных в форматах Excel или csv, описанный в нем процесс работает для любого табличного набора данных и научит вас, как выполнять прогнозы и использовать возможности Windows ML для вашего собственного уникального бизнес-кейса.
Обучите модель регрессии с несколькими метками с помощью PyTorch
В руководстве демонстрируются эти возможности анализа данных путем прогнозирования вида цветка ириса на основе его числовых измерений. Для обучения мы использовали известный набор данных Фишера, который включает записи о видах ирисов.
Вы можете использовать любой другой набор табличных данных для обучения вашей модели и прогнозирования желаемого результата. Однако важно указать входные и выходные данные модели на основе вашего набора данных и вашего сценария. В процессе обучения модель будет рассматривать взаимосвязь между входными и выходными данными и научится предсказывать результат.
На последнем этапе подготовки данных вы преобразуете входные и выходные данные модели в тензорный (Tensor) формат, поскольку для моделей машинного обучения требуется тензорное представление значений (многомерный массив). К счастью, очень легко преобразовать входные данные модели в тензоры с помощью PyTorch, используя пакет torch.Tensor PyTorch. В этом руководстве мы преобразуем входные данные набора данных с помощью всего нескольких строк кода.

Чтобы обучить модель нейронной сети, руководство проведет вас через процесс загрузки данных, определения параметров модели, модели и функции потерь, обучения модели на обучающем наборе и проверки модели с помощью набора проверки. В конце процесса обучения вы узнаете, как протестировать модель с помощью тестового набора данных.

Класс нейронной сети Pytorch nn.Module обеспечивает простой способ построения нейронной сети. Вам нужно только определить прямую функцию, так как обратная функция будет определена автоматически.
Изучите руководство, чтобы узнать, как создать обучающую функцию для перебора данных, передачи входных данных в сеть и оптимизации. После нескольких итераций по обучению можно ожидать достижения относительно высокой точности.

Развертывание модели с помощью API машинного обучения Windows
После обучения модели вы можете развернуть ее в приложении машинного обучения Windows, которое может работать на любом устройстве Windows. В руководстве показано, как создать все классы и методы для вызова API-интерфейсов машинного обучения Windows, которые загружают, связывают входные и выходные данные и оценивают вашу модель машинного обучения.

WindowsML API поддерживает все типы функций ONNX четырех описательных классов: тензоры, последовательность, карта и изображение. Это руководство поможет вам определить правильные входные данные на основе требований вашей модели. Чтобы создать тензорный ввод с помощью Windows ML API, вы можете использовать класс TensorFloat для определения 32-битного тензорного объекта с плавающей запятой. Этот класс предоставляет несколько методов для создания тензора – в этом руководстве мы используем метод CreateFromArray для создания входных данных тензора с точным размером, который требуется вашей модели.
Метод CreateFromArray требует двух параметров – массива видов и массива тензорных данных. Сам тензор – это просто список значений – наши данные, а массив видов сообщает вам, как интерпретировать массив данных. Если вы следовали руководству, модель сетевой регрессии, которую вы построили в предыдущей части, имеет четыре входных значения, каждое из которых представляет возможные размеры четырех физических характеристик цветка ириса. Размер пакета определяет количество выборок, которые будут распространяться по сети – в нашем случае размер пакета равен 1. Итак, форма входного тензора равна [1 × 4]. Этот массив видов сообщает вам, что массив данных имеет 2 измерения. Первое измерение имеет длину 1, а второе измерение – длину 4.

Начало работы
Завершив часть кода машинного обучения, вы можете легко интегрировать свою модель с приложением Windows. И если вам нужен ярлык, чтобы увидеть все это в действии, вы можете просмотреть полный образец кода в нашем репозитории GitHub – «Образец анализа данных», чтобы получить доступ к готовому приложению Windows. Это предварительно созданное приложение включает в себя графический интерфейс приложения и код управления пользовательским интерфейсом – все, что вам нужно для тестирования вашей модели!

Просматривая руководство, дайте нам знать, если у вас есть какие-либо предложения или вопросы, оставив отзыв о документации или примерах. Следите за обновлениями в блоге Windows AI!
Руководство по Создание приложения машинного обучения Apache Spark в Azure HDInsight
Из этого руководства вы узнаете, как с помощью Jupyter Notebook создать приложение машинного обучения Apache Spark для Azure HDInsight.
MLlib — это библиотека машинного обучения Apache Spark, состоящая из общих алгоритмов и служебных программ обучения (Классификация, регрессия, кластеризация, совместная фильтрация и уменьшение размерности, а также базовые примитивы оптимизации.)
В этом руководстве описано следующее:
- разработка приложения машинного обучения Apache Spark.
Предварительные требования
- Кластер Apache Spark в HDInsight. Ознакомьтесь со статьей Краткое руководство. Создание кластера Apache Spark в HDInsight с помощью шаблона.
- Опыт работы с записными книжками Jupyter с Spark в HDInsight. Дополнительные сведения см. в статье Руководство. Загрузка данных и выполнение запросов в кластере Apache Spark в Azure HDInsight.
Общие сведения о наборе данных
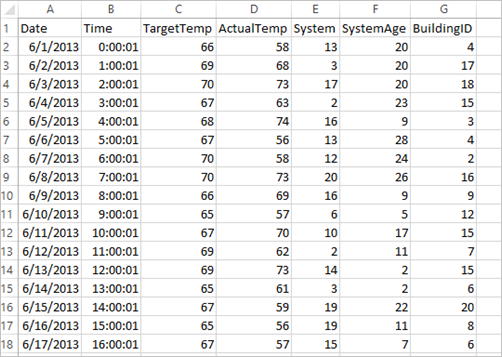
Приложение использует данные из примера файла HVAC.csv, который по умолчанию доступен на всех кластерах. Файл находится в папке \HdiSamples\HdiSamples\SensorSampleData\hvac . Это данные о целевой температуре и фактической температуре некоторых зданий, в которых установлена система кондиционирования воздуха. В столбце System указан идентификатор системы, а в столбце SystemAge — срок эксплуатации системы кондиционирования в годах. Вы можете спрогнозировать, будет ли температура здания выше или ниже относительно целевой температуры на основе идентификатора системы и срока ее эксплуатации.
Разработка приложения машинного обучения Spark с помощью Spark MLlib
В этом приложении используется конвейер машинного обучения Spark для выполнения классификации документов. Конвейеры машинного обучения предоставляют универсальный набор интерфейсов API высокого уровня, построенных на основе DataFrames. DataFrames позволяют создавать и настраивать практичные конвейеры машинного обучения. В конвейере вы разобьете документ на слова, преобразуете слова в вектор числового признака и, наконец, создадите модель прогнозирования с помощью вектора и меток признаков. Выполните следующие действия, чтобы создать приложение.
- Создайте записную книжку Jupyter Notebook с помощью ядра PySpark. Инструкции см. в разделе Создание файла записной книжки Jupyter Notebook.
- Импортируйте типы, необходимые для этого сценария. Вставьте следующий фрагмент кода в пустую ячейку и нажмите клавиши SHIFT + ВВОД.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithSGD from pyspark.mllib.regression import LabeledPoint from numpy import array # Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF() tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr]) model = pipeline.fit(training) training.show() Выходные данные должны быть следующего вида.
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+ 
Сравнение выходных данных со сведениями в необработанном CSV-файле. Например, в первой строке CSV-файла содержатся следующие данные: Обратите внимание на то, насколько фактическая температура меньше целевой, что свидетельствует о том, что здание холодное. Значение в первой строке столбца label составляет 0,0. Это означает, что в здании не жарко.
Подготовьте набор данных, в отношении которого необходимо выполнить обученную модель. Для этого передайте идентификатор системы и данные о сроке эксплуатации системы (обозначается как SystemInfo в выходных данных обучения). Модель прогнозирует, будет ли здание, оборудованное системой с этим идентификатором и сроком эксплуатации, теплее (значение 1,0) или холоднее (значение 0,0).
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([(1L, "20 25"), (2L, "4 15"), (3L, "16 9"), (4L, "9 22"), (5L, "17 10"), (6L, "7 22")]) \ .map(lambda x: Document(*x)).toDF() # Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print row Выходные данные должны быть следующего вида.
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985])) Использование библиотеки scikit-learn Anaconda для машинного обучения Spark
Кластеры Apache Spark в HDInsight включают библиотеки Anaconda. Они также включают библиотеку scikit-learn для машинного обучения. Кроме того, библиотека включает различные наборы данных, которые можно использовать для создания примеров приложений прямо в записной книжке Jupyter Notebook. Примеры использования библиотеки scikit-learn см. здесь: https://scikit-learn.org/stable/auto_examples/index.html.
Очистка ресурсов
Если вы не собираетесь использовать это приложение в дальнейшем, удалите созданный кластер, сделав следующее:
- Войдите на портал Azure.
- В поле Поиск в верхней части страницы введите HDInsight.
- Выберите Кластеры HDInsight в разделе Службы.
- В списке кластеров HDInsight, который отобразится, выберите . рядом с кластером, созданным при работе с этим учебником.
- Выберите команду Удалить. Выберите ответ Да.
Дальнейшие действия
Из этого руководства вы узнали, как с помощью Jupyter Notebook создать приложение машинного обучения Apache Spark для Azure HDInsight. Перейдите к следующему руководству, чтобы научиться использовать IntelliJ IDEA для заданий Spark.
Четыре урока о создании инструментов для машинного обучения

Мне хотелось бы поделиться с вами одними из самых удивительных выводов о том, как создавать оснастку для машинного обучения, что необходимо для движения вперёд и почему в будущем ИИ гораздо большую роль будут играть специалисты в предметных областях.
На протяжении прошлого года Humanloop создавала новый вид инструмента для обучения и внедрения моделей natural language processing (NLP). Мы помогали командам юристов, сотрудников службы поддержки, маркетологов и разработчиков ПО быстро обучать способные понимать речь ИИ-модели, а затем мгновенно их использовать. Начали мы с применения активного обучения, чтобы снизить потребность в аннотированных данных, но при этом поняли, что требуется гораздо больше.
На самом деле нам был необходим новый набор инструментов и рабочих процессов, изначально спроектированных для решения сложных задач работы с ИИ. Ниже мы расскажем о том, чему научились.
1. Специалисты в предметной области так же важны, как и дата-саентисты
В начале 2011 года спрос на экспертизу в глубоком обучении был настолько велик, что Джефф Хинтон продал себя на аукционе Google за 44 миллиона долларов. Сегодня всё уже не так.
Почти всё, что в 2011 году было в недостатке, сегодня стало общедоступным. Можно использовать современные модели, импортируя библиотеки, а большинство прорывов в исследованиях быстро внедряется. Даже получив PhD по глубокому обучению, я не устаю удивляться тому, насколько хорошо проявляют себя стандартные модели без предварительной подготовки в широком диапазоне способов применения.
Создавать сервисы машинного обучения по-прежнему сложно, но основной трудностью стало получение нужных данных.

— И это твоя система машинного обучения?
— Ага! Вливаешь данные в эту кучу линейной алгебры и собираешь ответы с другого конца.
— А если ответы неправильные?
— Тогда просто перетряхиваем кучу, пока они не будут выглядеть правильными.
Как ни удивительно, похоже, технические знания ML становятся менее полезными, чем экспертиза в предметной области.
Например, мы работали с командой, которая хотела узнать результат более 80 тысяч исторических судебных прецедентов. Ручная обработка этих документов была совершенно невозможна и стоила бы сотни тысяч долларов времени юристов. Для решения этой задачи сами по себе дата-саентисты были не очень полезны. На самом деле нам нужен был юрист.
В традиционном рабочем процессе data science аннотирование данных считается первым этапом перед обучением модели. Однако мы осознали, что если поставить в центр рабочего процесса аннотирование/курирование данных, то результаты можно получить гораздо быстрее. Это позволяет взять на себя инициативу специалистам в предметной области и упростить для них взаимодействие с дата-саентистами. По нашим наблюдениям, это приводит к повышению качества данных и моделей.
Команда из двух юристов аннотировала данные на платформе Humanloop, а модель параллельно автоматически обучалась при помощи активного обучения. Всего за несколько часов юристы обучили модель, выдавшую результат 80 тысяч судебных прецедентов вообще без участия дата-саентистов.
Однако это справедливо не только для юристов. Мы наблюдали, как команды врачей выполняли аннотирование для обучения медицинских чат-ботов, как финансовые аналитики выполняли разметку для распознавания именованных сущностей, а учёные аннотировали данные для крупномасштабного поиска статей.
2. Первая итерация всегда выполняется для определения классов разметки
Обучение модели ML обычно начинается с разметки массива данных. Когда мы изначально создавали платформу Humanloop, то думали, что этап выбора классов для разметки выполняется в начале проекта, и на этом он заканчивается.
Большинство команд недооценивает сложность выбора правильной классификации разметки без предварительного изучения данных
Вскоре мы осознали, что как только команды начинают размечать данные, они обнаруживают, что их начальные предположения о необходимых категориях ошибочны. Обычно в данных возникали классы, о которых никто не думал, или которые были настолько редкими, что их лучше было скомбинировать в более широкую категорию. Также команды часто удивляются тому, как сложно добиться консенсуса в определении того, что же означают даже простые классы.
После начала проекта почти всегда между дата-саентистами, менеджерами проектов и аннотаторами возникают споры о том, как обновлять классы разметки.
Поставив курирование данных в центр рабочего процесса ML, вы сильно упрощаете достижение консенсуса среди ответственных лиц. Чтобы ещё больше упростить этот процесс, мы добавили менеджерам проектов возможность редактировать классы разметки в процессе аннотирования. Модель и система активного обучения Humanloop автоматически учитывают любые изменения в разметке. Мы дали командам возможность помечать, комментировать и обсуждать примеры данных.
3. ROI быстрой обратной связи огромен
Одним из неожиданных преимуществ созданной нами платформы активного обучения стало то, что она позволила быстро прототипировать модели и снижать риск проектов. В процессе аннотирования командой на платформе Humanloop модель обучается в реальном времени и предоставляет статистику о своей производительности.
Многие из проектов машинного обучения завершаются неудачно. Согласно данным algorithmia, до 87% проектов не добирается до этапа продакшена. Часто причина заключается в нечёткости целей, слишком низком качестве входящих данных для прогнозирования результатов, или развитие моделей застревает, не дождавшись вывода в продакшен. Высшее руководство начинает с неохотой выделять ресурсы на проекты, имеющие высокую степень неопределённости, поэтому многие хорошие возможности оказываются упущенными.
Хотя мы этого и не планировали, но осознали, что команды используют быструю обратную связь Humanloop для оценки реалистичности проектов. Загружая небольшой массив данных и размечая несколько примеров, команды добиваются понимания того, как может продвигаться их проект. Это означало, что часть проектов, которая могла провалиться, не двигалась дальше, а другая часть быстро получала больше ресурсов, потому что команды знали, что они сработают. Зачастую эти исследования на ранних этапах выполнялись менеджерами проектов, вообще не имеющими опыта в машинном обучении.
4. Инструменты ML должны быть ориентированы на данные, но в основе иметь модель
Большинство существующих инструментов для обучения и внедрения машинного обучения (MLOps) построено по типу традиционного ПО. Они делают упор на код, а не на данные и нацелены на узкие срезы конвейера разработки ML. Существуют инструменты MLOps для мониторинга, для хранения признаков, для управления версиями моделей, для управления версиями данных, для оценки и так далее. Почти ни один из этих инструментов на деле не изучает и не разбирается в данных, на которых обучаются системы.
В последнее время от таких людей, как Эндрю Ын и Андрей Карпати слышится призыв к созданию ориентированных на данные инструментов ML. Мы полностью согласны с тем, что для машинного обучения команды должны делать гораздо больший упор на массивы данных, но выяснили, что наилучшая версия этих инструментов должна быть тесно связана с моделью.
Большинство преимуществ, наблюдаемых при работе с платформой Humanloop, возникает в результате взаимодействия между данными и моделью:
- В процессе исследования: модель выявляет редкие классы и обеспечивает обратную связь об уровне сложности обучения категориям.
- В процессе обучения: модель находит данные, имеющие наибольшую ценность при разметке, чтобы можно было получить высокопроизводительные модели при меньшем количестве меток.
- При проверке: модель сильно упрощает поиск ошибочных аннотаций. Платформа Humanloop выявляет примеры, в которых прогноз модели с высокой степенью уверенности расходится с мнением разметчиков-специалистов в предметной области. Поиск и исправление ошибочно размеченных точек данных часто может быть наиболее эффективным способом улучшения производительности модели.
Мы считаем, что начав со сферы NLP, за прошлый год совершили существенные шаги в создании новых инструментов, сильно упрощающих машинное обучение. Мы стали свидетелями того, как специалисты в предметной области множества отраслей делают свой вклад в обучение ИИ-моделей, и нам не терпится узнать, какие ещё новые приложения будут построены на основе Humanloop.
- разметка данных
- data labeling
- машинное обучение
- data annotation
- software
- dataset
- Training Data
- инструменты для разметки
- разметка датасета
- активное обучение
- active learning
- human in the loop
- Data Mining
- Big Data
- Машинное обучение
- Искусственный интеллект
- Natural Language Processing
При подготовке материала использовались источники:
https://habr.com/ru/companies/microsoft/articles/574698/
https://learn.microsoft.com/ru-ru/azure/hdinsight/spark/apache-spark-ipython-notebook-machine-learning
https://habr.com/ru/articles/648739/